While 2022 can be characterized by many challenges that each and every person and society as a whole faced, at the end of this year, I would like to refer to only the positive things it has brought me, for which I am exceptionally grateful! This year has been really full of very different events and experiences, so it is great to take a second and realize what has happened so far – in such a dynamic world, it is sometimes difficult to keep track of everything that has happened in a certain period of time, so it is worthwhile doing it for yourself!
Probably the first thing that comes in mind is a big change that took place in my life, i.e. the fact that this year I joined University of Tartu (Faculty of Science and Technology, Institute of Computer Science, Chair of Software Engineering)) as an assistant professor of Information Systems.
At the same time, I had a great experience of acting as a visiting researcher at the Delft University of Technology, Faculty of Technology, Policy and Management. This was a 6-months long research “visit”, which due to COVID-19 pandemic, however, took place online, although I still got a nice experience, including communication with many TU Delft colleagues, including discussions that we established during my participation in a monthly ICT colloquium, one of which was dedicated to my research. During this research visit, together with my esteemed colleague Anneke Zuiderwijk we launched a study in which we revisit the barriers associated with the publication of government data as OGD by public agencies, not only because it is a dynamic topic, where factors related to the intent and resistance to this tend to change, but also because the pandemic has changed views on the value and usefulness of the OGD, with the reference to both perspective – provision and usage. Thus, we believe that these factors have changed. Considering the role of the OGD in the current society, we decided not to use almost “traditional” models such as TAM, UTAT, TOE etc., but to refer to another theory not previously used in e-government area, namely the Innovation Resistance Theory (IRT), which, however, has proved to be very useful in the field of business and management (though not only this discipline). Thus, the objective of this research is twofold – to test the appropriateness/ validity of this theory for the OGD and e-gov domains, as well as to revisit the barriers to publishing government data as an OGD, also checking whether COVID-19 has changed the state of affairs in this regard significantly. So far we have come up with the OGD-adapted IRT model, which we presented at ICEGOV2022, which was recognized as one of three best papers, nominated for best paper awards, which was an amazing conclusion to my “visit” to TU Delft. The study, however, continues even after the end of this visit.
To improve my skills and knowledge in areas of interest to me, this year I also attended two Summer Schools – 6th International Summer School on the Deep Learning called DeepLearn 2022, and the 9th International Summer School On Open and Collaborative Governance that took place in conjunction with the 12th Samos 2022 Summit on ICT-Enabled Governance.
But, of course, I tried not only to acquire and develop new knowledge and skills, but also to share them with others, including both my students, colleagues, students of my foreign colleagues, pupils, school teachers, industry and others. In addition, I was honored to participate in several events, acting as both the keynote, panelist, invited speaker, expert, guest of honor, and as a regular speaker discussing the hot topics, and presenting my own works. All in all, it was a busy and eventful year.
Even more, my work results were recognized and awarded several times this year – I was named and awarded as best moderator of Research and Innovation Forum 2022, got nominated for the best paper award of ICEGOV2022 – 15th International Conference on Theory and Practice of Electronic Governance, and got the best paper award of KMIS2022 – 14th International Conference on Knowledge Management and Information Systems in conjunction with the 14th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K).
I also was invited to join Editorial Board of several journals and was pleased to accept their kind invitation. All in all, starting with this year I am an Editorial Board member of eJournal of eDemocracy and Open Government (JeDEM), Area Editor of “Focus on Data-driven Transformations in Policy and Governance” for Data & Policy (Cambridge University Press), Politics of Technology section of Frontiers in Political Science. In addition, I served as an organizing and program committee for several conferences, acting as general co-chair for EGETC – Electronic Governance with Emerging Technologies Conference, part of organizing team for Data for Policy 2022 devoted to ecosystem of innovation and virtual-physical interaction, publicity chair for IDSTA – International Conference on Intelligent Data Science Technologies and Applications and MegaData – International Workshop on Advanced Data Systems Management, Engineering, and Analytics as part of IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID2023), session chair for KMIS (sessions “Big Data and Analytics” and “Knowledge management Strategies and Implementations”), IDSTA, and panel moderator for RiiForum – Research and Innovation Forum 2022, when for moderating the “Business in the era of pervasive digitalization” panel, I was awarded with the best panel moderator award.
Another activity that is closely related to the topic I am proud of, is the series of workshops I launched together with my colleagues devoted to the identification of determinants for identifying High-value Datasets titled “Identification of high-value dataset determinants: is there a silver bullet?“. The idea of referring to this topic came to my mind a long time ago, when the VARAM ministry of Latvia responsible for the OGD initiative and development and maintaining the OGD portal reached me first as one of people who could contribute to prioritization of the datasets to be potentially opened, and later with the reference to the concept of HVD. After conducting an analysis for Latvia, I decided to refer to this topic from a more scientific point of view, and now we have already two editions of the workshop in the pocket – one that took place during ICEGOV2022, and another one – as part of ICOD2022, where we managed to have interactive sessions with ~40 open data researchers and/or experts and brainstorm on this topic (read more).
As regards the role of PC member, I was honored to be invited to become such for several conferences, including: EGOV2022 – IFIP EGOV-CeDEM-EPART 2022 in conjunction with 23rd Annual International Conference on Digital Government Research”, Data for Policy 2022, ADBIS 2022 – 26th European Conference on Advances in Databases and Information Systems (Workshop on Advances Data Systems Management, Engineering, and Analytics), EGETC2022 – Electronic Governance with Emerging Technologies Conference, ICT2022 – International Conference on ICT, Society and Human Beings as part of the Multi Conference on Computer Science and Information Systems (MCCSIS2022), IHCI2022 – International Conference on Interfaces and Human Computer Interaction” also part of MCCSIS2022, IDSTA2022 – The International Conference on Intelligent Data Science Technologies and Applications, iLRN2022 – The International Conference of the Immersive Learning Research Network, RiiForum2022 – Research and Innovation Forum 2022, FedCSIS2022 / ISM2022 – Conference on Information Systems Management as part of the Conference on Computer Science and Intelligence Systems, ESWC2022 – International Workshop on Knowledge Graph Generation from Text (Text2KG) co-located with the Extended Semantic Web Conference, KGSWC2022 – Iberoamerican Knowledge Graph and Semantic Web. In addition, I try my best to find time for reviewing journal articles in top-level journals, when I am invited as an external reviewer. Although these activities take time, but those who are also doing this will definitely confirm that this is an exceptional opportunity to be used not only to provide the colleagues with an external view on the article and suggest how it could be improved, but also identify best-practices in writing and presenting ideas, identifying how your own works can be improved by either following these practices or avoiding them. Thus, I value these opportunities very much and try to find time to devote myself to this, particularly, if I understand that my input – review can be of value for authors. Here, at least a few journals that definitely deserved my gratitude are Technological Forecasting and Social Change, Government Information Quarterly, Technology in Society (Elsevier), Digital Policy, Regulation and Governance, Transforming Government: People, Process and Policy, Information and Learning Sciences, Online Information Review (Emerald), Scientific Data (Springer Nature), eJournal of eDemocracy and Open Government (JeDEM), International Journal of Human-Computer Interaction (IJHC), but actually all of those, where I contributed 🙂
And since I referred to both journals and conferences I was related to this year, it is the time to refer to my own contributions, i.e. some quantitative indicators.
This year 23 articles, including 3 book chapters, one extended abstract and one whitepaper were published, authored by me together with my colleagues, while some of them even with my students (some of them will be officially published in 2023, same as a few were written in 2021). 10 of them are journal articles, one – whitepaper published by European Commission, and 9 – conference papers:
- Lnenicka, M., Nikiforova, A., Luterek, M., Azeroual, O., Ukpabi, D., Valtenbergs, V., Machova, R. (2022) Transparency of open data ecosystems in smart cities: definition and assessment of the maturity of transparency in 22 smart cities, Sustainable Cities and Society, Q1, IF: 7.587
- Lněnička, M., Nikiforova, A., Saxena, S. and Singh, P. (2022), Investigation into the adoption of open government data among students: the behavioural intention-based comparative analysis of three countries, Aslib Journal of Information Management, Vol. 74 No. 3, pp. 549-567, Q1, IF: 2.343
- Nikiforova A., Zuiderwijk A. (2022) Barriers to openly sharing government data: towards an open data-adapted innovation resistance theory, In 15th International Conference on Theory and Practice of Electronic Governance (ICEGOV 2022). Association for Computing Machinery, New York, NY, USA, 215–220 – best paper award nominee
- Azeroual O., Schöpfel J., Pölönen J., and Nikiforova N. (2022). Putting FAIR principles in the context of research information: FAIRness for CRIS and CRIS for FAIRness. In Proceedings of the 14th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management,Vol. 3, pp. 63-71 – best paper award
- Nikiforova A. (2022) Gen Z open data hackathon – civic innovation with digital natives: to hack or not to hack, In Proceedings of Ongoing Research, Practitioners, Workshops, Posters, and Projects of the International Conference EGOV-CeDEM-ePart 2022, pp. 251-253, September 5-8, Linkoping, Sweden
- Lnenicka M., Luterek M., Nikiforova A. (2022) Benchmarking open data efforts through indices and rankings: Assessing development and contexts of use, Telematics and Informatics, 2021, 101745, Q1, IF: 6.182
- Saxena, S., Shao, D., Nikiforova, A. and Thapliyal, R. (2022), Invoking blockchain technology in e-government services: a cybernetic perspective, Digital Policy, Regulation and Governance, Vol. 24 No. 3, pp. 246-258
- Azeroual, O., Jha, M., Nikiforova, A., Sha, K., Alsmirat, M., & Jha, S. (2022). A Record Linkage-Based Data Deduplication Framework with DataCleaner Extension. Multimodal Technologies and Interaction, 6(4), 27
- Azeroual, O., Schöpfel, J., Ivanović, D., & Nikiforova, A. (2022). Combining Data Lake and Data Wrangling for Ensuring Data Quality in CRIS. Procedia Computer Science, Vol. 211, pp. 3-16
- Tékouabou, S. C. K., Jérôme C., Rida A., Hamza T., El Bachir D., and Anastasija Nikiforova. 2022. Identifying and Classifying Urban Data Sources for Machine Learning-Based Sustainable Urban Planning and Decision Support Systems Development, Data 7, no. 12: 170.
- Salminen J., Mustak M., Rizun N., Revina A., Nikiforova A., Almerekhi H., Jung S., Jansen B.J. (2022) Integrating AI into Customer Service: Improving the Actionability of Customer Feedback Analysis Using Machine Learning, in Proceedings of the 4th international conference on AIRSI2022 Technologies 4.0 in Tourism, Services & Marketing
- Azeroual, O., Nikiforova, A. Apache Spark and MLlib-Based Intrusion Detection System or How the Big Data Technologies Can Secure the Data. Information 2022, 13, 58
- Nikiforova A., Rovite V., Tiwari S., Klovins J., Kante N., Evaluation and visualization of healthcare semantic models, Editor(s): Sanju Tiwari, Fernando Ortiz Rodriguez, M.A. Jabbar, In Intelligent Data-Centric Systems, Semantic Models in IoT and Ehealth Applications, Academic Press, 2022, pp. 39-68
- Chang V., Xiao L., Nikiforova A., Xu Q., Liu B. (2022) The Study of PGP Web of Trust Based on Social Network Analysis, International Journal of Business Information Systems
- Chang, V., Marshall, R., Xu, Q. A., & Nikiforova, A. (2023). E-commerce assistant application incorporating machine learning image classification. International Journal of Business and Systems Research, 17(1), 1-26
- Nikiforova A., Data security as a top priority in the digital world: preserve data value by being proactive and thinking security first, In Research and Innovation Forum 2022, edited by Anna Visvizi, Orlando Troisi, Mara Grimaldi, 2022, Springer Nature Switzerland AG (Gewerbestrasse 11, 6330 Cham, Switzerland)
- Nikiforova, A. (2022). Open data hackathon as a tool for increased engagement of Generation Z: to hack or not to hack?, 2022 Electronic Governance with Emerging Technologies Conference, Springer
- Nikiforova, A., Flores, M. A., & Lytras, M. D. (2022). The role of open data in the transformation to Society 5.0: a resource or a tool for SDG-compliant Smart Living?, In Smart Cities and the Next Generation: Empowering Communities, Limitless Innovation, Emerald Publishing Limited, 2023 (accepted, in print)
- Ishengoma, F.R., Shao, D., Alexopoulos, C., Saxena, S. and Nikiforova, A. (2022), “Integration of artificial intelligence of things (AIoT) in the public sector: drivers, barriers and future research agenda“, Digital Policy, Regulation and Governance, Vol. 24 No. 5, pp. 449-462
- Govoruhina A., Nikiforova A. (2022) Digital health shopping assistant with React Native: a simple technological solution to a complex health problem, 2022 International Conference on Intelligent Data Science Technologies and Applications (IDSTA), 2022, pp. 34-40,
- Kumar N., Jilani A. K., Kumar P., Nikiforova A. (2022). Improved YOLOv3-tiny Object Detector with Dilated CNN for Drone-Captured Images, 2022 International Conference on Intelligent Data Science Technologies and Applications (IDSTA), 2022, pp. 89-94
- Nikiforova A., Daskevics A., Otmane A., “NoSQL security: can my data-driven decision-making be affected from outside?,” in: Visvizi, A., Troisi, O., Grimaldi, M. (eds) (2023) Big Data and Decision-Making: Applications and Uses in the Public and Private Sector (Emerald Studies in Politics and Technology), Bingley, UK: Emerald Publishing
- Wilkinson, M., Sansone, S., Méndez, E., David, R., Dennis, R., Hecker, D., Lacagnina, C., Nikiforova, A., & Castro, L. (2022). Community-driven Governance of FAIRness Assessment: An Open Issue, an Open Discussion. Open Research Europe 2022, 2:146
The first study listed above, i.e. “Transparency of open data ecosystems in smart cities: Definition and assessment of the maturity of transparency in 22 smart cities” (Lnenicka, Nikiforova, Luterek, Azeroual, Dandison, Valtenbergs, Machova) was noticed by the Living Library that seeks to provide actionable knowledge on governance innovation, informing and inspiring policymakers, practitioners, technologists, and researchers working at the intersection of governance, innovation, and technology in a timely, digestible and comprehensive manner, identifying the “signal in the noise” by curating research, best practices, points of view, new tools, and developments… Proud to see our joint article there (read more…)
Similarly, The Open Data Institute hosted micro-site on the exploration of the future of data portals and citizen engagement (led by Rachel Wilson, in collaboration with ODI Associate Consultant Tim Davies) publishes a series of very insightful posts reflecting on the most prospective studies to take stock of the state of portals, and explore possible futures, where two of them reflect on my previous studies, namely Transparency-by-design: What is the role of open data portals? (Lnenicka, M. and Nikiforova, A. 2021, Telematics and Informatics 61), Open government data portal usability: A user-centred usability analysis of 41 open government data portals (Nikiforova & McBride, Telematics and Informatics), Benchmarking open data efforts through indices and rankings: Assessing development and contexts of use (Lnenicka, Luterek & Nikiforova, Telematics and Informatics), Timeliness of Open Data in Open Government Data Portals Through Pandemic-related Data: A long data way from the publisher to the user (Nikiforova, 2020 Fourth International Conference on Multimedia Computing, Networking and Applications (MCNA))! (read more#1…) (read more#2…)
This year I participated in 10 international conferences, where 9 papers (co-)authored by me were presented, with 2 conferences, where I chaired my (co-)organized workshops, with another conference, where I acted as a keynote speaker, and some more other events of more national and/or regional nature. Some of them are:
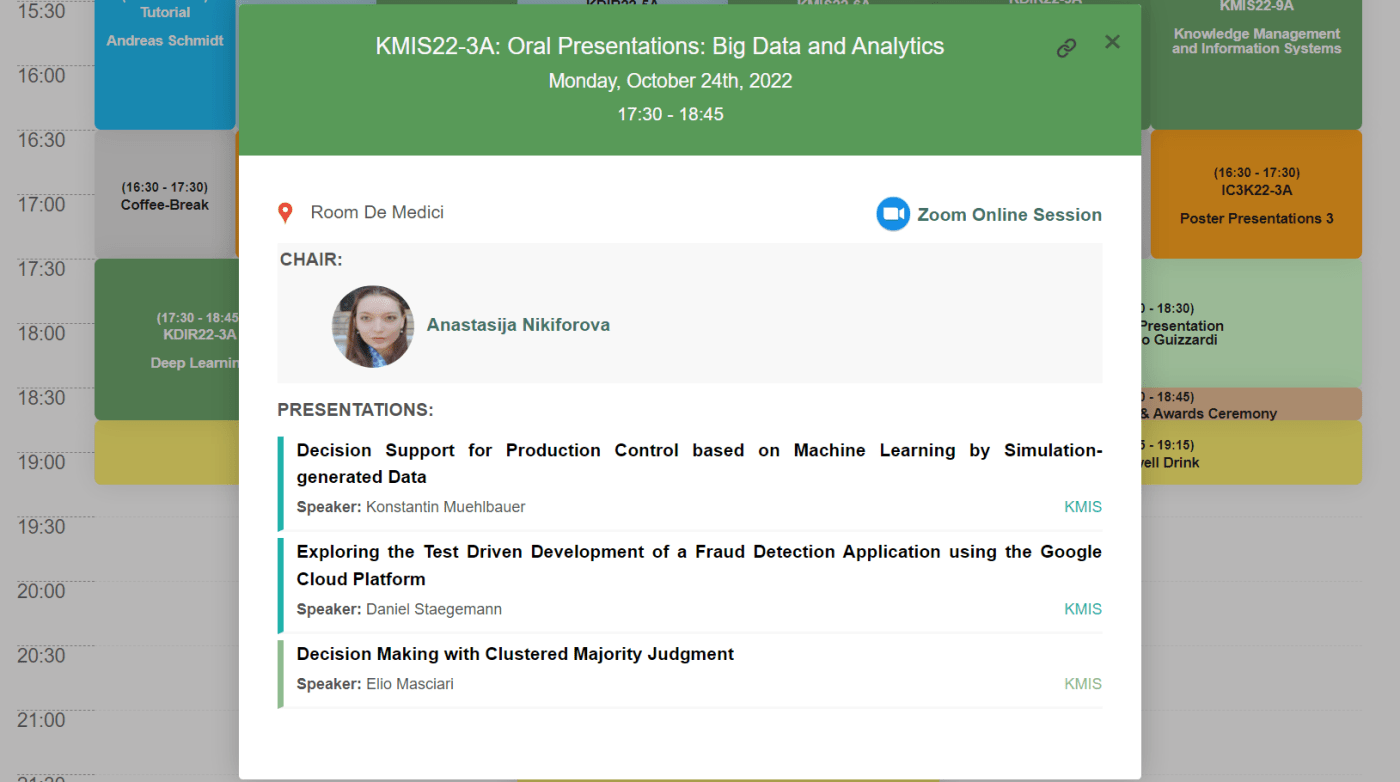
- KMIS2022 – 14th International Conference on Knowledge Management and Information Systems in conjunction with 14th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K), and received best paper award for our paper titled “Putting FAIR Principles in the Context of Research Information: FAIRness for CRIS and CRIS for FAIRness” (O. Azeroual, J. Schöpfel, J. Pölönen and A. Nikiforova);
- ICEGOV2022 – 15th International Conference on Theory and Practice of Electronic Governance “Digital Governance for Social, Economic, and Environmental Prosperity”, where in addition to the workshop I organized and chaired, our paper authored together with Anneke Zuiderwijk and titled “Barriers to openly sharing government data: towards an open data-adapted innovation resistance theory” was recognized to be one of the best papers of the conference – we were nominated to the Best Paper Awards;
- EGOV2022 – IFIP EGOV-CeDEM-EPART 2022 in conjunction with 23rd Annual International Conference on Digital Government Research, where I acted as both speaker and PC member;
- IDSTA2022 – International Conference on Intelligent Data Science Technologies and Applications, where I acted as both speaker (two papers were accepted), session chair and publicity chair;
- ICOD2022 – International Conference on Open Data: open data challenges in times of crises and growth;
- EGETC2022 – Electronic Governance with Emerging Technologies Conference, where I acted as both speaker, PC member, and general chair;
- ISGOV2022 – International Innovation and Smart Government Conference, where I delivered a keynote talk “Data as an asset for Sustainable Development of data-driven Smart Cities and Smart Society”;
- AIRSI2022 Technologies 4.0 in Tourism, Services & Marketing;
- Research and Innovation Forum 2022 (RiiForum2022), where I acted as both speaker, presenting my study, PC member, panel organizer (“Security of data storage facilities: is your database sufficiently protected?” as a part of the track called “ICT, safety, and security in the digital age: bringing the human factor back into the analysis“), and a moderator of the panel “Business in the era of pervasive digitalization“. For the later, i.e. moderation of the panel, I was awarded with the best panel moderator award!
- CRIS2022 – 15th International Conference on Current Research Information Systems (CRIS2022) – Linking Research Information across data spaces,
- ONE Conference 2022 (Health, Environment, Society) – panelist of the “ONE society” thematic track, panel discussion “Turning open science into practice: causality as a showcase” as a data quality expert;
- The 12th Samos 2022 Summit on ICT-Enabled Governance ;
- “Integration of open data and artificial intelligence in the development of smart cities in Africa” workshop organized as part of the African Cities Lab Project, where I was invited as a keynote speaker with the talk on “Open data and crowdsourced data as enablers and drivers for smart African cities”
- European Food Safety Authority (EFSA) and Evidence-Based Toxicology Collaboration (EBTC) joint workshop for setting the scene on the creation of a standard for data exchange in support of automation of Systematic Review, where I acted as a speaker / expert.
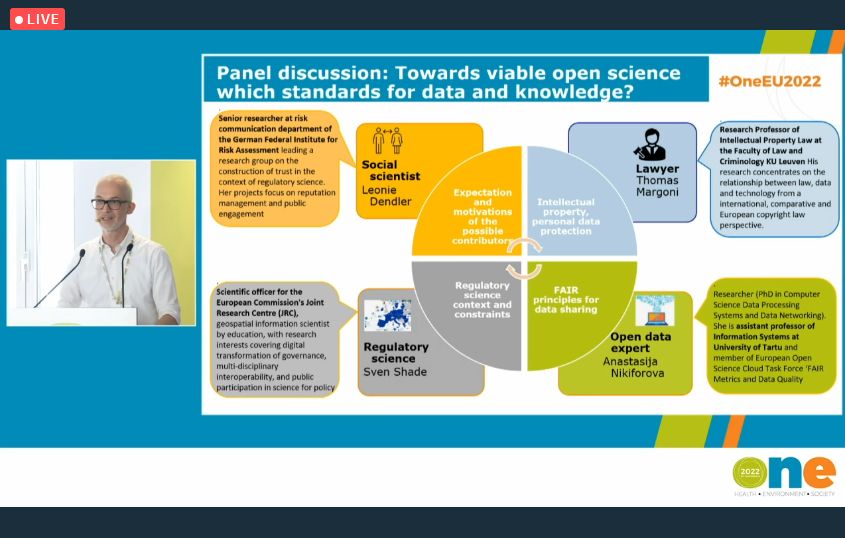
From the above, let me emphasize one event, which was very specific for me since it was my first experience as a panelist, especially in such a “crowded” event (due to a very high rate of the attendance) – ONE Conference 2022 (Health, Environment, Society), which took place between June 21 and 24, Brussels, Belgium. It was co-organised by European Food Safety Authority (EFSA) and its European sister agencies European Environment Agency, European Medicines Agency, European Chemicals Agency, European Centre for Disease Prevention and Control (ECDC), but if you are an active follower of my blog, you know this already (I posted about this event previously). As a person representing not only academia, but also EOSC (European Open Science Cloud) and dealing with the topics of data quality and open data, I was invited to serves as a panelist of the “ONE society” thematic track, panel discussion “Turning open science into practice: causality as a showcase”. It was a very nice experience and opportunity for sharing our experience on obstacles, benefits and the feasibility of adopting open science approaches, and elaborate on the following questions (although they were more but these one are my favorites): Can the use of open science increase trust to regulatory science? Or does it increase the risk to lose focus, introduce conflicting interests and, thus, threaten reputation? What are the barriers to make open science viable in support to the scientific assessment process carried out by public organizations? What are the tools/ methods available enabling, supporting and sustaining long term open science initiatives today and what could be envisaged for the future? Do we need a governance to handle open data in support to scientific assessment processes carried out by regulatory science bodies? How the data coming from different sources can be harmonized making it appropriate for further use and combination?
And as a follow-up for this event, I was kindly invited by EFSA to contribute to setting the scene on the concept of ‘standards for data exchange’, ‘standards for data content’ and ‘standards for data generation’ as part of European Food Safety Authority (EFSA) and Evidence-Based Toxicology Collaboration (EBTC) ongoing project on the creation of a standard for data exchange in support of automation of Systematic Review (as the answer to the call made in “Roadmap for actions on artificial intelligence for evidence management in risk assessment”). It was really nice to know that what we are doing in EOSC Association (Task Force “FAIR metrics and data quality”) is of interest for our colleagues from EFSA and EBTC. Also, it was super nice to listen other points of view and get involved in the discussion with other speakers and organisers and I am looking forward the first draft expected to be ready by the end of this year.
Since this is so much about the open science, as well as I already mentioned EOSC, probably it is worthwhile to mention that we just got published our – EOSC Task Force on FAIR Metrics and Data Quality whitepaper “Community-driven Governance of FAIRness Assessment: An Open Issue, an Open Discussion” (Mark D. Wilkinson; Susanna-Assunta Sansone; Eva Méndez; Romain David; Richard Dennis; David Hecker; Mari Kleemola; Carlo Lacagnina; Anastasija Nikiforova; Leyla Jael Castro), which is published by European Commission, of course, in an open access, here. In it we emphasize that although FAIR Research Data Principles are targeted at and implemented by different communities, research disciplines, and research stakeholders (data stewards, curators, etc.), there is no conclusive way to determine the level of FAIRness intended or required to make research artefacts (including, but not limited to, research data) Findable, Accessible, Interoperable, and Reusable. The FAIR Principles cover all types of digital objects, metadata, and infrastructures. However, they focus their narrative on data features that support their reusability. FAIR defines principles, not standards, and therefore they do not propose a mechanism to achieve the behaviours they describe in an attempt to be technology/implementation neutral. A range of FAIR assessment metrics and tools have been designed that measure FAIRness. Unfortunately, the same digital objects assessed by different tools often exhibit widely different outcomes because of these independent interpretations of FAIR. This results in confusion among the publishers, the funders, and the users of digital research objects. Moreover, in the absence of a standard and transparent definition of what constitutes FAIR behaviours, there is a temptation to define existing approaches as being FAIR-compliant rather than having FAIR define the expected behaviours. This whitepaper identifies three high-level stakeholder categories -FAIR decision and policymakers, FAIR custodians, and FAIR practitioners – and provides examples outlining specific stakeholders’ (hypothetical but anticipated) needs. It also examines possible models for governance based on the existing peer efforts, standardisation bodies, and other ways to acknowledge specifications and potential benefits. This whitepaper can serve as a starting point to foster an open discussion around FAIRness governance and the mechanism(s) that could be used to implement it, to be trusted, broadly representative, appropriately scoped, and sustainable. We invite engagement in this conversation, while more detail on both the whitepaper, as well as how to get engaged in this conversation, you can find here.
Here, let me also mention another activity – Guest Lectures, which this year I delivered to students of the Federal University of Technology – Parana (UTFPR, Brazil) and, more precisely so-called PPGEP program – Postgraduate Program in Production Engineering (port. Programa de Pós-Graduação em Engenharia de Produção), and to students of University of South-Eastern Norway (USN) – this was already my second time of delivering a guest lecture for USN. The first lecture was titled “The role of open data in the development of sustainable smart cities and smart society“, in scope of which I was pleasured to raise a discussion on three topics of particular interest – open data, Smart City, and Society 5.0, which are actually very interrelated, while the second – “Open data as a catalyst for collaborative, data-driven smart cities and smart society: what is the key to success?”. Both lectures inspired me a lot since were accompanied with a lively discussion around touched topics, which is always a pleasure for the lecturer.
In addition to some lectures delivered to actual students, some of my talks were delivered to people outside academia as well.
As an example, in February I got yet another experience by participating in a programme launched by Riga TechGirls and supported by Google.org (“Google Impact challenge” grant), in addition to local supporters such as the Ministry of Education and Science of Latvia, the Ministry of Culture, Riga city council (Rīgas Dome), titled “Human on technology” for more than 2000 Latvian teachers with the aim of disrupting technophobia and provide them with digital skills that are “must-have” in this digital world/ era. I have acted as both the lecturer and the lead mentor for the digital development workshop held as a part of the “Information and data literacy” module (read more…)
While the above event was dedicated to adults, another experience was to work with pupils representing Generation Z – this year, although same as in previous years, I have been a mentor of the Latvian Open Data Hackathon and an idea generator for pupils, organized by the Latvian Open Technologies Association with the support of DATI Group, E-Klase, Latvijas Kultūras akadēmija / Latvian Academy of Culture, Vides aizsardzības un reģionālās attīstības ministrija (VARAM)/ Ministry of Environmental Protection and Regional Development of Republic of Latvia and others. This year the main topic of the hackathon was cultural heritage, where within a month, 36 teams from 126 participants from all over Latvia developed their ideas and prototypes, 10 teams reached the final after a round of semi-final presentations of their solutions to us – the mentor team (of course, we worked with the assigned teams in previous weeks as well). Here, we not only evaluated these ideas, but also provided them with yet another portion of feedback and suggestions for improving the idea or prototype for its further presentation in the final, where the jury will finally decide who the winner is. The participants surprised us (mentors) very much both with the diversity of ideas and in very many times with their technical knowledge and skills (AI, crowdsourcing, gamification to name just a few) – just wow!
In the continuation of the topic of hackathon, I am interested in, researching it a bit as well, I also participated in the Hack the hackathon (Vol. 2) workshop organized by the Flatiron Institute (New York, NY, USA), the purpose of which was to bring together researchers of different disciplines studying hackathons and hackathon practitioners from different communities to meet and discuss the current state of practice and research around hackathons as well as future challenges. I also had the honor of being one of the participants, who was invited to deliver a short talk on practical experience within a topic to be further discussed and brainstormed by all of us, which, obviously, was related to the above topic and was entitled “Gen Z hackathons: digital natives for hackathons or hackathons for digital natives?”. Unfortunately, considering my schedule at that point, when I really needed Time-Turner, I did not managed to dive into this event in the way I wanted to (even considering the opportunity to participate online, which I used), but this was still a very lively event, full of emotions (positive)!
And as I mentioned before, another “set” of activities were related to the industry. Here, there are three events that I enjoyed very much, namely:
- “Virtual Brown Bag Lunch Talks” intended for the Information Technologies, Manufacturing, and Engineering Employees in Companies associated with Index Manufacturing Association, where I was invited to delivered a talk “Data Security as a top priority or what Internet of Things (IoT) Search engines know about you“, which is based on several studies conducted by me before. Probably the most interesting point to be mentioned that this event was intended for Mexican audience, which was definitely something new for me. We had an exceptionally interesting discussion after my talk with representatives of the industry to whom these events are made, and I was super delighted to get so many positive comments, which definitely makes this event something to be in the list;
- another very interesting “foreign” experience I had is related to the Babu Banarasi Das University (BBDU, Department of Computer Science and Engineering) Development Program «Artificial Intelligence for Sustainable Development» organized by AI Research Centre, Department of Computer Science & Engineering, Babu Banarasi Das University (India), ShodhGuru Research Labs, Soft Computing Research Society, IEEE UP Section, Computational Intelligence Society Chapter, where I was invited to deliver a talk, which I decided to devote to two topics I am interested in, which I titled “Artificial Intelligence for Open Data or Open Data for Artificial Intelligence?”. While previous event was based in Mexico (I participate online, of course), this one was intended for India and Indian representatives from industry interested in advances in the field of Artificial Intelligence, which were more than 130 people. In this talk, I not only provided an insights on both topics, and what can opportunities the combination of these pehnomenons provide us with, but also about the other side of the coin, i.e., this “magic duo” is not always about “unicorns and ice creams“, where the current state-of-the-art suggests that open data my pose also certain risks (read more here);
- continuing this “journey”, this summer, while participating in a Summer school on e-government I referred to previously, I also had a pleasure to participate in one more exceptionally interested event – “Integration of open data and artificial intelligence in the development of smart cities in Africa” workshop organized as part of the African Cities Lab Project conducted by representatives of both academia, industry and government from Morocco, Ghana, Tunisia, South Africa, Rwanda, Benin, Switzerland, where I was invited as a keynote speaker and delivered the talk “Open data and crowdsourced data as enablers and drivers for smart African cities”. Again, after the talk we had an extremely interesting discussion, when the discussion about how to develop the OGD initiative in African cities, where the support for this is very limited, we managed to raise very interesting questions and I came to several new ideas, about which I have never thought before, for which I am very grateful to those participants, who were actively involved in this discussion!
- but, of course, one local event I enjoyed very much should also be mentioned here – Data Science Seminar titled “When, Why and How? The Importance of Business Intelligence“ seminar organized by the Institute of Computer Science (University of Tartu) in cooperation with Swedbank, in which the importance of BI with some focus on data quality was discussed. The seminar consisted of four talks, which were followed by a panel moderated by my colleague prof. Marlon Dumas – 2 talks were delivered by representatives of the University of Tartu, where we both decided to focus our talks on data quality. Here I was invited to deliver a talk on one of studies I was recently involved in, and I titled it – “Data Lake or Data Warehouse? Data cleaning or data wrangling? How to ensure the quality of your data?“. Again, the discussions followed after the talk and also a discussion established as part fof the panel we had were both incredibely interesting and allowed us to exchange our ideas, experience and thought on the future development of related concepts, which is probably the best outcome of any event (read more).
This is a short overview of the activities carried out and the events in which I took part this year. As follows from the variety of these events, I met many people (virtually and physically), some of them became my colleagues, others – also friends. All in all, this is also about people. People who support you, people who believe in you, and people who respect you and whom you respect. My wish to myself and all of you is to have only such people around – those who respect you, whom you respect (very much), those who support you, and not only if there is an urgent need for this support, but simply because they want to be there and provide you with their continuous support, those who not only respect your current works and achievements, but those who believe that you can and will definitely be able achieve even more!
And the last thing to say here, of course, is – thank you, 2022 for all those positive things and emotions you brought, and bye! Welcome 2023!!!