Proud to be part of the EOSC Task Force on FAIR Metrics and Data Quality and present our whitepaper “Community-driven Governance of FAIRness Assessment: An Open Issue, an Open Discussion” (Mark D. Wilkinson; Susanna-Assunta Sansone; Eva Méndez; Romain David; Richard Dennis; David Hecker; Mari Kleemola; Carlo Lacagnina; Anastasija Nikiforova; Leyla Jael Castro) published by European Commission, of course, in an open access, here.
“Although FAIR Research Data Principles are targeted at and implemented by different communities, research disciplines, and research stakeholders (data stewards, curators, etc.), there is no conclusive way to determine the level of FAIRness intended or required to make research artefacts (including, but not limited to, research data) Findable, Accessible, Interoperable, and Reusable.
The FAIR Principles cover all types of digital objects, metadata, and infrastructures. However, they focus their narrative on data features that support their reusability. FAIR defines principles, not standards, and therefore they do not propose a mechanism to achieve the behaviours they describe in an attempt to be technology/implementation neutral.
FAIR is evolving in some expected and some unexpected ways. FAIR “Reusability” sub-principle R1.3 states that “(meta)data should meet domain-relevant community standards,” which predicts a proliferation of FAIR interpretations by individual communities as they select their preferred approach to FAIRness. Similarly, as expected, there is an active movement around the adaptation of the FAIR Principles to digital objects other than data (e.g., software and workflows), again with individual communities interpreting what FAIRness means in these expanded contexts. However, there have also been attempts to expand the FAIR Principles themselves in recent years, including features of digital objects beyond reusability, including popularity (reuse/citation), reproducibility, reliability, data quality, etc. All of this is occurring with no overall coordination or planning.
A range of FAIR assessment metrics and tools have been designed that measure FAIRness. Unfortunately, the same digital objects assessed by different tools often exhibit widely different outcomes because of these independent interpretations of FAIR. This results in confusion among the publishers, the funders, and the users of digital research objects. Moreover, in the absence of a standard and transparent definition of what constitutes FAIR behaviours, there is a temptation to define existing approaches as being FAIR-compliant rather than having FAIR define the expected behaviours. While it is anticipated that communities will define domain-specific FAIR metrics and tests, it is desirable to avoid “gaming the system” and have broadly agreed-upon approaches to FAIRness that do not favour a specific implementation of technology.
These observations suggest a growing need to align the different interpretations of the FAIR Principles. However, this whitepaper does not suggest that the FAIR Principles themselves require governance. Indeed, the document argues that the Principles should remain untouched. Specialised communities should extend/edit those Principles to adapt and make them more relevant to their community and their specific research outcome intended to be FAIR.
This whitepaper identifies three high-level stakeholder categories -FAIR decision and policymakers, FAIR custodians, and FAIR practitioners – and provides examples outlining specific stakeholders’ (hypothetical but anticipated) needs. It also examines possible models for governance based on the existing peer efforts, standardisation bodies, and other ways to acknowledge specifications and potential benefits. This whitepaper can serve as a starting point to foster an open discussion around FAIRness governance and the mechanism(s) that could be used to implement it, to be trusted, broadly representative, appropriately scoped, and sustainable”
Cite as: Mark D. Wilkinson, Susanna-Assunta Sansone, Eva Méndez, Romain David, Richard Dennis, David Hecker, Mari Kleemola, Carlo Lacagnina, Anastasija Nikiforova, & Leyla Jael Castro. (2022). Community-driven Governance of FAIRness Assessment: An Open Issue, an Open Discussion [version 1; peer review: awaiting peer review]. Open Res Europe 2022, 2:146 (https://doi.org/10.12688/openreseurope.15364.1)
In this post I would like to briefly elaborate on a truly insightful 14th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K), where I was honored to participate as a speaker, presenting our paper “Putting FAIR principles in the context of research information: FAIRness for CRIS and CRIS for FAIRness” (authors: Otmane Azeroual, Joachim Schopfel and Janne Polonen, and Anastasija Nikiforova), and as a chair of two absolutely amazing sessions, where live and fruitful discussions took place, which is a real indicator of the success of such! And spoiler, our paper was recognized as the Best Paper! (i.e., best paper award goes to… :))
IC3K consists of three subconferences, namely 14th International Conference on Knowledge Discovery and Information Retrieval (KDIR), 14th International Conference on Knowledge Engineering and Ontology Development (KEOD), and 14th International Conference on Knowledge Management and Information Systems (KMIS), where the latter is the one, to which my paper has been accepted, and also won the Best Paper Award – I know, this is a repetition, but I am glad to receive it, same as the euroCRIS community is proud for us – read more here…!
Briefly about our study, with which we mostly wanted to urge a call for action in the area of CRIS and their FAIRness. Of course, this is all about the digitization, which take place in various domain, including but not limited to the research domain, where it refers to the increasing integration and analysis of research information as part of the research data management process. However, it is not clear whether this research information is actually used and, more importantly, whether this information and data are of sufficient quality, and value and knowledge could be extracted from them. It is considered that FAIR principles (Findability, Accessibility, Interoperability, Reusability) represent a promising asset to achieve this. Since their publication (by one of the colleagues I work together in European Open Science Cloud), they have rapidly proliferated and have become part of both national and international research funding programs. A special feature of the FAIR principles is the emphasis on the legibility, readability, and understandability of data. At the same time, they pose a prerequisite for data and their reliability, trustworthiness, and quality. In this sense, the importance of applying FAIR principles to research information and respective systems such as Current Research Information Systems (CRIS, also known as RIS, RIMS), which is an underrepresented subject for research, is the subject of our study. What should be kept in mind is that the research information is not just research data, and research information management systems such as CRIS are not just repositories for research data. They are much more complex, alive, dynamic, interactive and multi-stakeholder objects. However, in the real-world they are not directly subject to the FAIR research data management guiding principles. Thus, supporting the call for the need for a ”one-stop-shop and register-once use-many approach”, we argue that CRIS is a key component of the research infrastructure landscape / ecosystem, directly targeted and enabled by operational application and the promotion of FAIR principles. We hypothesize that the improvement of FAIRness is a bidirectional process, where CRIS promotes FAIRness of data and infrastructures, and FAIR principles push further improvements to the underlying CRIS. All in all, three propositions on which we elaborate in our paper and invite everyone representing this domain to think of, are:
1. research information management systems (CRIS) are helpful to assess the FAIRness of research data and data repositories;
2. research information management systems (CRIS) contribute to the FAIRness of other research infrastructure;
3. research information management systems (CRIS) can be improved through the application of the FAIR principles.
Here, we have raised a discussion on this topic showing that the improvement of FAIRness is a dual or bidirectional process, where CRIS promotes and contributes to the FAIRness of data and infrastructures, and FAIR principles push for further improvement in the underlying CRIS data model and format, positively affecting the sustainability of these systems and underlying artifacts. CRIS are beneficial for FAIR, and FAIR is beneficial for CRIS. Nevertheless, as pointed out by (Tatum and Brown, 2018), the impact of CRIS on FAIRness is mainly focused on the (1) findability (“F” in FAIR) through the use of persistent identifiers and (2) interoperability (“I” in FAIR) through standard metadata, while the impact on the other two principles, namely accessibility and reusability (“A” and “R” in FAIR) seems to be more indirect, related to and conditioned by metadata on licensing and access. Paraphrasing the statement that “FAIRness is necessary, but not sufficient for ‘open’” (Tatum and Brown, 2018), our conclusion is that “CRIS are necessary but not sufficient for FAIRness”.
This study differs significantly from what I typically talk about, but it was to contribute to it, thereby sharing the experience I gain in European Open Science Cloud (EOSC), and respective Task Force I am involved in – “FAIR metrics and data quality”. It also allowed me to provide some insights on what we are dealing with within this domain and how our activities contribute to the currently limited body of knowledge on this topic.
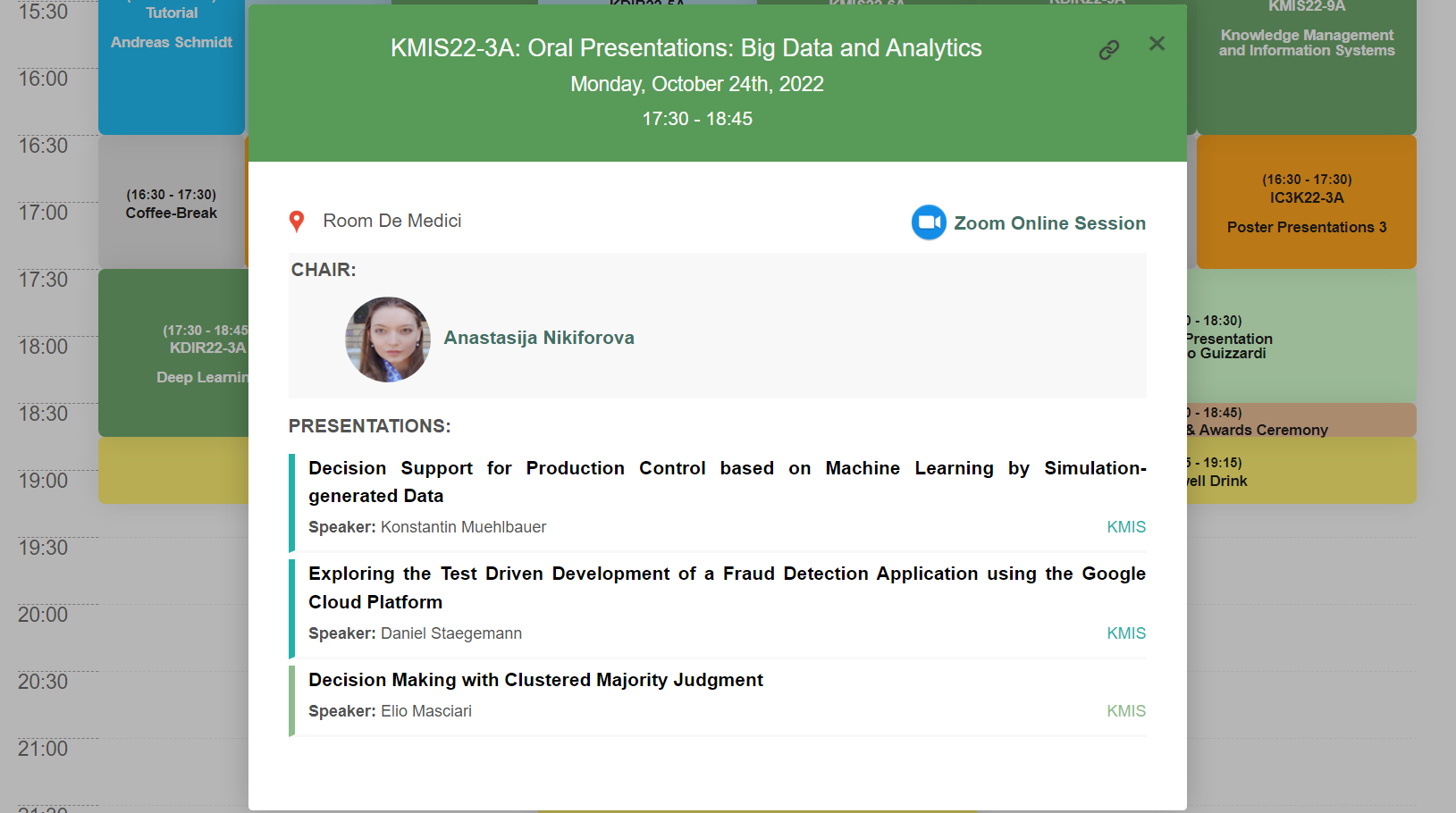
A bit about the sessions I chaired and topics raised within them, which were very diverse but equally relevant and interesting. I was kindly invited to chair two sessions, namely “Big Data and Analytics” and “Knowledge management Strategies and Implementations”, where the papers on the following topics were presented:
Decision Support for Production Control based on Machine Learning by Simulation-generated Data (Konstantin Muehlbauer, Lukas Rissmann, Sebastian Meissner, Landshut University of Applied Sciences, Germany);
Exploring the Test Driven Development of a Fraud Detection Application using the Google Cloud Platform (Daniel Staegemann, Matthias Volk, Maneendra Perera, Klaus Turowski, Otto-von-Guericke University Magdeburg, Germany) – this paper was also recognized as the best student paper;
Decision Making with Clustered Majority Judgment (Emanuele D’ajello , Davide Formica, Elio Masciari, Gaia Mattia, Arianna Anniciello, Cristina Moscariello, Stefano Quintarelli, Davide Zaccarella, University of Napoli Federico II, Copernicani, Milano, Italy.
Virtual Reality (VR) Technology Integration in the Training Environment Leads to Behaviour Change (Amy Rosellini, University of North Texas, USA)
Innovation in Boutique Hotels in Valletta, Malta: A Multi-level Investigation (Kristina, University of Malta, Malta)
And, of course, as is the case for each and every conference, the keynotes are panelists are those, who gather the highest number of attendees, which is obvious, considering the topic they elaborate on, as well as the topics they raise and discuss. IC3K is not an exception, and the conference started with a very insightful discussion on Current Data Security Regulations and the discussion on whether they Serve or rather Restrict the Application of the Tools and Techniques of AI. Each of three speakers, namely Catholijn Jonker, Bart Verheijen, and Giancarlo Guizzardi, presented their views considering the domain they represent. As a result, both were very different, but at the same time leading you to “I cannot agree more” feeling!
One of panelists – Catholijn Jonker (TU Delft) delivered then an absolutely exceptional keynote speech on Self-Reflective Hybrid Intelligence: Combining Human with Artificial Intelligence and Logic. Enjoyed not only the content, but also the style, where the propositions are critically elaborated on, pointing out that they are not indented to serve as a silver bullet, and the scope, as well as side-effects should be determined and considered. Truly insightful and, I would say, inspiring talk.
All in all, thank you, organizers – INSTICC (Institute for Systems and Technologies of Information, Control and Communication), for bringing us together!
Considering that in last weeks I was pretty active in delivering very many talks, let me use this post to summarize some of them thereby remaining them in my memory as well as allowing you, my dear reader, to pick up some ideas or navigate to some projects (both projects, initiatives, postgraduate programs, joint workshops or “lunchs” for business and academia) of your interest. So this post is less about self-advertisement and my role in the below discussed events as both panelist, keynote, guest lecturer, invited speaker and expert, but more about very interesting projects, initiatives and labs currently running in different countries and at different scales – local, national, regional and international. And as “thank you” for the organizers of each of them, I would like to shed a light on them in this post, drawing your attention to them!
All in all, this post is about participating as a panelist for One Conference 2022, keynote for African Smart Cities Lab projects’ workshop (Morocco, Ghana, Tunisia, South Africa, Rwanda, Benin, Switzerland), Guest Lecture for master and doctoral students of the Federal University of Technology – Paraná (UTFPR, Postgraduate Program in Production Engineering, Brasil), and invited speaker / expert for monthly “Virtual Brown Bag Lunch” (Mexico), and EFSA & EBTC joint project (Italy) on the creation of a standard for data exchange in support of automation of Systematic Review.
So, let’s start with the most spontaneous, namely “Integration of open data and artificial intelligence in the development of smart cities in Africa” workshop organized as part of the African Cities Lab Project, where I was invited as a keynote speaker. Actually, African Smart Cities Lab project is a very interesting initiative I recently was glad to get familiar with. It is a joint initiative led by École polytechnique fédérale de Lausanne (Switzerland), the Kwame Nkrumah’ University of Science and Technology, Kumasi (Ghana), the UM6P – Mohammed VI Polytechnic University (Maroc), Sèmè City campus (Benin), the Faculty of Sciences of Bizerta – University of Carthage (Tunisia), the University of Cape Town (South Africa), and the University of Rwanda that aims to create a digital education platform on urban development in Africa, offering quality MOOC and online, continuing education training for professionals. It is also expected to act as a forum for the exchange of digital educational resources and the management and governance of African cities to foster sustainable urban development. The very first workshop took place July 5 in an online mode, where 9 speakers were invited to share their experience on this topic and allow setting the scene for the development of African Smart Cities, considering their potential, but also some bottlenecks.
All in all, two very fruitful sessions with presentations delivered by me, Vitor Pessoa Colombo, Constant Cap, Oualid Ali, Jérôme Chenal, Nesrine Chehata, AKDIM Tariq, Christelle Gracia Gbado, Willy Franck Sob took place and raised a lot of questions, finding the answers for many of them. My talk was titled “Open data and crowdsourced data as enablers and drivers for smart African cities” (see slides below…)
Here, let me immediately mention another activity – a Guest Lecture “The role of open data in the development of sustainable smart cities and smart society“, I delivered to students of the Federal University of Technology – Parana (UTFPR, Brazil) and, more precisely so-called PPGEP program – Postgraduate Program in Production Engineering (port. Programa de Pós-Graduação em Engenharia de Produção), in scope of which I was pleasured to raise a discussion on three topics of particular interest – open data, Smart City, and Society 5.0, which are actually very interrelated. This also allowed me to refer to one of our recent studies – Transparency of open data ecosystems in smart cities: definition and assessment of the maturity of transparency in 22 smart cities– published together with my colleagues – Martin Lnenicka, Mariusz Luterek, Otmane Azeroual, Dandison Ukpabi, Visvadis Valtenbergs, and Renata Machova in Sustainable Cities and Society (Q1, Impact Factor: 7.587, SNIP: 2.347, CiteScore: 10.7).
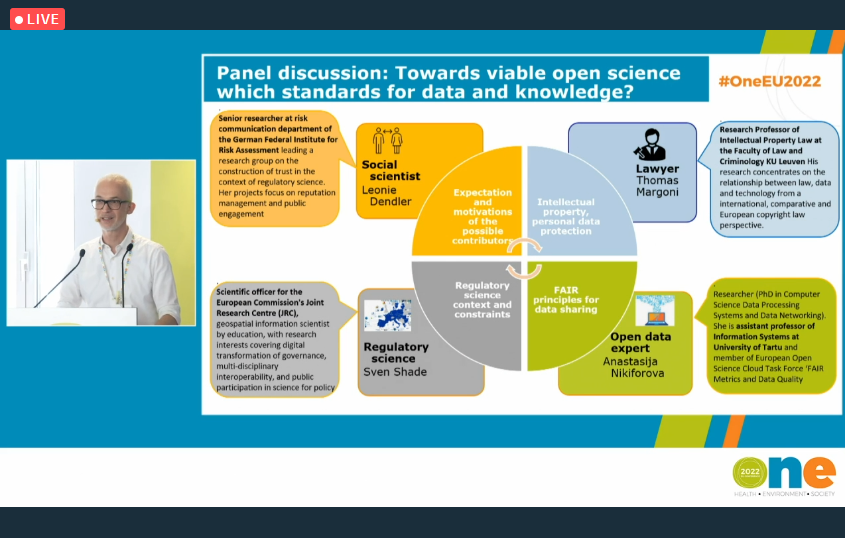
And now, it’s time to turn to two events organized by European Food Safety Authority (EFSA). The first and probably the most “crowded” due to a very high rate of the attendance was the ONE Conference 2022 (Health, Environment, Society), which took place between June 21 and 24, Brussels, Belgium. It was co-organised by European Food Safety Authority (EFSA) and its European sister agencies European Environment Agency, European Medicines Agency, European Chemicals Agency, European Centre for Disease Prevention and Control (ECDC), but if you are an active follower of my blog, you know this already, same as probably remember that I posted about this event previously inviting you to join us in Belgium or online. Since I have elaborated on the course of the event, its main objectives and tracks, I will not repeat this information. Instead, let me briefly summarize key takeaways with a particular focus on the panel for which I served as a panelist – the “ONE society” thematic track, panel discussion“Turning open science into practice: causality as a showcase”. It was a very nice experience and opportunity for sharing our experience on obstacles, benefits and the feasibility of adopting open science approaches, and elaborate on the following questions (although they were more but these one are my favorites): 💡Can the use of open science increase trust to regulatory science? Or does it increase the risk to lose focus, introduce conflicting interests and, thus, threaten reputation? What are the barriers to make open science viable in support to the scientific assessment process carried out by public organizations? 💡What are the tools/ methods available enabling, supporting and sustaining long term open science initiatives today and what could be envisaged for the future? 💡Do we need a governance to handle open data in support to scientific assessment processes carried out by regulatory science bodies? 💡How the data coming from different sources can be harmonized making it appropriate for further use and combination?
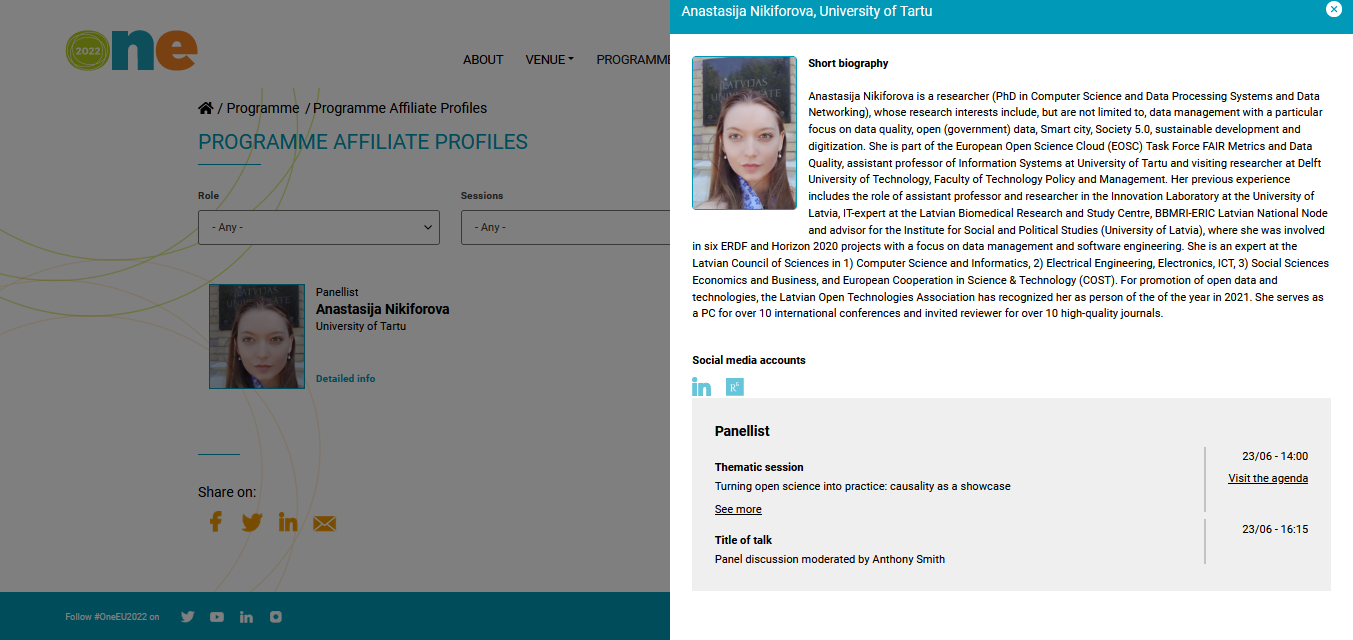
These and many more questions were discussed by panelists with different background and expertise, which were nicely presented by European Food Safety Authority (EFSA) breaking down our experience in four categories – social science (Leonie Dendler, German Federal Institute for Risk Assessment BfR), open data expert (Anastasija Nikiforova,) EOSC Association, University of Tartu, Institute of Computer Science, lawyer (Thomas Margoni, KU Leuven ), regulatory science (Sven Schade, Joint Research Centre, EU Science, Research and Innovation). Many thanks Laura Martino, Federica Barrucci, Claudia Cascio, Laura Ciccolallo, Marios Georgiadis, Giovanni Iacono, Yannick Spill (European Food Safety Authority (EFSA)), and of course to Tony Smith and Jean-François Dechamp (European Commission). For more information, refer to this page.
And as a follow-up for this event, I was kindly invited by EFSA to contribute to setting the scene on the concept of ‘standards for data exchange’, ‘standards for data content’ and ‘standards for data generation’ as part of European Food Safety Authority (EFSA) and Evidence-Based Toxicology Collaboration (EBTC) ongoing project on thecreation of a standard for data exchange in support of automation of Systematic Review (as the answer to the call made in “Roadmap for actions on artificial intelligence for evidence management in risk assessment”). It was really nice to know that what we are doing in EOSC Association (Task Force “FAIR metrics and data quality”) is of interest for our colleagues from EFSA and EBTC. Also, it was super nice to listen other points of view and get involved in the discussion with other speakers and organisers – Elisa Aiassa, Angelo Cafaro, Fulvio Barizzone, Ermanno Cavalli, Marios Georgiadis, Irene Pilar, Irene Muñoz Guajardo, Federica Barrucci, Daniela Tomcikova, Carsten Behring, Irene Da Costa, Raquel Costa, Maeve Cushen, Laura Martino, Yannick Spill, Davide Arcella, Valeria Ercolano, Vittoria Flamini, Kim Wever, Gunn Vist, Annette Bitsch, Daniele Wikoff, Carlijn Hooijmans, Sebastian Hoffmann, Seneca Fitch, Paul Whaley, Katya Tsaioun, Alexandra Bannach-Brown, Ashley Elizabeth Muller, Anne Thessen, Julie McMurray, Brian Alper, Khalid Shahin, Bryn Rhodes, Kaitlyn Hair. The next workshop is expected to take place in September with the first draft ready by the end of this year and presented during one of the upcoming events. More info on this will follow 🙂
In addition, I was asked by my Mexican colleagues to deliver an invited talk for monthly “Virtual Brown Bag Lunch Talks” intended for the Information Technologies, Manufacturing, and Engineering Employees in Companies associated with Index Manufacturing Association (Mexico, web-based). After discussing several topics with the organizers of this event, we decided that this time the most relevant talk for the audience would be “Data Security as a top priority or what Internet of Things (IoT) Search engines know about you“. Again, if you are an active follower, you will probably realize quickly that it is based on a list of my previous studies – study#1, study#2, study#3 and book chapter.
Certificates from Universidad Autononma de Tamaulipas & Index (Mexico) and Universidad Techlogica Federal de Parana (Brasil)
All in all, while these were just a few activities I was busy with during the last weeks and, these weeks were indeed very busy but extreeeemely interesting with so many different events! I am grateful to all those people, who invited me to take part in them and believe that this is just one of the opportunities we had to collaborate and there are many more in the future!
Briefly about the workshop, our motivation, our objective and why we want to make you a part of it…
Today, Open Government Data (OGD) are seen as one of the trends that can potentially benefit the economy, improve the quality, efficiency, and transparency of public services, as well as transform our lives contributing to efficient sustainability-oriented data-driven development. Their scope, as well as actors who can work with them, do not meet any restrictions. In addition to “classical” benefits such as improving the quality, efficiency, and transparency of public services, they are considered drivers and promoters of Industry 4.0 and Society 5.0 [1,2], including Smart cities trends. OGD is also a driver of economic growth, and, according to [3], the open data market size in 2020 was estimated at €184 billion and it is expected to grow in the coming years reaching €199.51 and €334.21 billion in 2025. However, the achievement of these benefits is closely linked to the “value” of the data, i.e. the extent to which the data provided by public agencies are interesting, useful and valuable for their reuse, creating value for society and the economy. High data availability however can disorient users when deciding which sources are best suited to their needs [4]. The practice demonstrates that the majority of data sets available on the OGD portals are not used, where only a few datasets create value for users [5], [6]. This is also in line with Quarati and Martino [4], who provided a snapshot on the use of 15 OGD portals, based on usage indicators available. This also applies to Latvia [7,8]. In other words, in order to gain benefit from the OGD, countries should open data cleverly, where not quantity, but quality and data value must be more important, since all benefits of the OGD can only be obtained if the data are re-used and transformed to value.
Here, the concept of “high-value datasets” comes, pointing to data that would create highest value to society and economy. The concept of “high-value data” comes into force here. High-value data are defined as the data “the re-use of which is associated with important benefits for society, the environment and the economy, in particular because of their suitability for the creation of value-added services, applications and new, high-quality and decent jobs, and of the number of potential beneficiaries of the value-added services and applications based on those datasets” [9]. Although the PSI directive is a step in this direction by announcing six categories [9], they appear to be generic and do not take into account the national perspective, i.e. the nature of these data sets will depend to a large extent on the country concerned [10,11]. It is therefore important to support the identification of high-value datasets, which would enhance the interest of users of the OGD by transforming data in innovative solutions and services. The research suggests that different perspectives appear in the literature to identify “high-value datasets” and there is no consensus on the most comprehensive, so a number of activities will be taken covering these perspectives but prior identified within the workshop.
This workshop expects to raise a discussion on the identification of high-value data sets for a common understanding of how this could be done in general terms, i.e. what possible activities will lead to better understanding and clearer vision of what are the most valuable data sets for the society and economics of a particular country and how they can be identified (how? who? etc.). The topic under consideration is very important these days, given that the opening up of data sets with high potential for their use and re-use is expected to facilitate creation of new products or services with positive economic and social impact [12]. However, identifying these data is a complicated task, particularly where country-specific data sets should be identified.
This workshop is a step in this direction and is a continuation of the paper presented at ICEGOV2021 [13], where a first step in this direction was taken by conducting a survey of individual users and SME of Latvia aimed at clarifying their level of awareness about the existence of the OGD, their usage habits, as well as the overall level of satisfaction with the value of the OGD and their potential. This time we aim to develop the framework for identification of high-value datasets (and their determinants) as a result of comprehensive study conducted jointly with participants of ICEGOV. All in all, the objective of the workshop is to raise awareness of and establish a network of the major stakeholders around the HVD issue, allow each participant to think about how and whether the determination of HVD is taking place in their country and how this can be improved with the help of portal owners, data publishers, data owners and citizens. Our main motivation is that, as members of the ICEGOV community, we could jointly answer the following questions representing the objectives of the workshop:
How can the “value” of open data be defined?
What are the current indicators for determining the value of data? Can they be used to identify valuable datasets to be opened? What are the country-specific high-value determinants (aspects) participants can think of?
How high-value datasets can be identified? What mechanisms and/ or methods should be put in place to allow their determination? Could it be there an automated way to gather information for HVD? Can they be identified by third parties, e.g. researchers, enthusiasts AND potential data publishers, i.e. data owners?
What should be the scope of the framework, i.e. who should be the target audience who should be made aware of the HVD applying this framework? public officials / servants? data owners? Intermediaries? (discussion with participants OR direction for our discussion depending on the participants and their profile).
More precisely, the following “procedure” is expected to be followed:
STEP 0 (conducted by participants (not mandatory)): participants are invited to get familiar with open data portals of their country (higher coverage, i.e. of more than their own country, is welcome) by inspecting the current state-of-the-art in terms of both the content – data available, functionality with particular interest of HVD determination-related features (if any) including citizen-engagement-oriented features, features allowing to track the current interest of users etc.
STEP 1: A brief introduction to the current state-of-the art [approximately 45 minutes]: How HVD are seen by the PSI Directive and what tasks are set for countries regarding determination and opening HVD, how countries are coping with this (both from grey literature and from personal experience on Latvia), what approaches and methods for determining HVDs are known and why is there no uniform method / framework?A brief overview of the results of a survey of individual users and small and medium-sized businesses (SME) of Latvia on their view regarding the current state of the data, i.e. in which extent they meet their needs, and what data might be useful for them, and how their availability would affect their willingness to use these data.Overview of Deloitte report on HVD. What is the methodology used? What are the indicators used? What are the results of the study?
STEP 2: Considering the diversity of perceptions of the term “value” (depending on the domain, actor etc.), the discussion in the form of brainstorming (idea generation) is expected to be held providing as many definitions as possible, which are then used to provide a more comprehensive definition(s) considering different perspectives (domain- and actor-related) [approximately 30-45 minutes]
STEP 3: Discussion on current methods / mechanisms to determine the current value of the data and determining HVD in the form of brainstorming [approximately 20-30 minutes]
STEP 4: Idea generation on potential methods / mechanisms to determine the current value of the data and determining HVD in the form of brainstorming [approximately 20-30 minutes]
STEP 5: Iterative filtering of features, methods, approaches that could constitute the framework for determination of high value datasets in the form of DELPHI-like analysis [approximately 45 minutes]
STEP 6: Agenda for future research, networking [approximately 30 minutes]
This is a community-based, participatory, interactive workshop aimed at engaging participants – instead of asking participants to write a paper to be later presented during the workshop in the form of sit-and-listen, we expect to establish a lively and interesting discussion of novel ideas, answering existing questions and raising new ones. The audience of the workshop is ICEGOV participants without restriction on the domain they represent, affiliation, interests, knowledge and experience. Both OGD experts and those who are not familiar with OGD are welcome.
Join us this October (4 – 7 October 2022)!
References:
Bargiotti, L., De Keyzer, M., Goedertier, S., & Loutas, N. (2014). Value based prioritisation of Open Government Data investments. European Public Sector Information Platform.
Bertot, J. C., McDermott, P., & Smith, T. (2012, January). Measurement of open government: Metrics and process. In 2012 45th Hawaii International Conference on System Sciences (pp. 2491-2499). IEEE.
Directive (EU) 2019/1024 of the European Parliament and of the Council of 20 June 2019 on open data and the re-use of public sector information
Gagliardi, D., Schina, L., Sarcinella, M. L., Mangialardi, G., Niglia, F., & Corallo, A. (2017). Information and communication technologies and public participation: interactive maps and value added for citizens. Government Information Quarterly, 34(1), 153-166.
Huyer, E., Blank, M. (2020). Analytical Report 15: High-value datasets: understanding the perspective of data providers. Luxembourg: Publications Office of the European Union, 2020 doi:10.2830/363773
Kampars, J., Zdravkovic, J., Stirna, J., & Grabis, J. (2020). Extending organizational capabilities with Open Data to support sustainable and dynamic business ecosystems. Software and Systems Modeling, 19(2), 371-398.
Kotsev, A., Cetl, V., Dusart, J., & Mavridis, D. (2018). Data-driven Economies in Central and Eastern Europe
Kucera, J., Chlapek, D., Klímek, J., & Necaský, M. (2015). Methodologies and Best Practices for Open Data Publication. In DATESO (pp. 52-64).
McBride, K., Toots, M., Kalvet, T., & Krimmer, R. (2019). Turning Open Government Data into Public Value: Testing the COPS Framework for the Co-creation of OGD-Driven Public Services. In Governance Models for Creating Public Value in Open Data Initiatives (pp. 3-31). Springer, Cham.
Nikiforova, A., & Lnenicka, M. (2021). A multi-perspective knowledge-driven approach for analysis of the demand side of the Open Government Data portal. Government Information Quarterly, 101622
Ruijer, E., Détienne, F., Baker, M., Groff, J., & Meijer, A. J. (2020). The politics of open government data: Understanding organizational responses to pressure for more transparency. The American review of public administration, 50(3), 260-274
Nikiforova, A. (2021, October). Towards enrichment of the open government data: a stakeholder-centered determination of High-Value Data sets for Latvia. In 14th International Conference on Theory and Practice of Electronic Governance (pp. 367-372).
Since June 2022, I am an Editorial Board Member of theeJournal of eDemocracy and Open Government (JeDEM) – a platinum/diamond scholarly-led Open Access e-journal managed by an interdisciplinary team of scholars at the Department for E-Governance and Administration at Danube University Krems, Austria. Its new Chief Editor – an external scholar in the journal’s key area, who is invited every 4 years to advice on the journal’s strategy – is Anneke Zuiderwijk with whom I was proud to collaborate very actively as part of my research visit to Delft University of Technology, Faculty Technology Policy and Management.
JeDEM is interested in both theoretical, practical and empirical research in the categories Research Papers, Invited Papers, Project Descriptions and Reflections. Within this scope, JeDEM particularly welcomes, but is not limited to, submissions related to the following topics:
e-Democracy
ICT and communication technologies to promote democracy or (re-)democratization;
Digital Divide, social inclusion and related political strategies;
Data Divide and algorithmic accountability;
policy analysis;
the role of security and privacy;
democratic innovation, governance models and alternative solutions.
e-Society and e-Participation
civic technologies and platforms (e.g. evaluation, critical and innovative approaches, national or international solutions);
collaborative decision-making and participatory budgeting;
the role of civil society and organizations;
stakeholder analysis, tool assessment and evaluation (e.g. political parties, government);
analysis of platform engagement (e.g. semantic analysis, computational or discourse analytical approaches);
co-decision, co-creation, co-production, decision-making and e-voting.
e-Government
general government services, evaluation of public policies (e.g. platforms for digital communication, virtual organizations and solutions, organizational training);
decision-making, Artificial Intelligence and automatization;
environmental, social and smart governance solutions;
governmental innovation.
Open data, including both social and technical aspects and the intersection between them
open data policy, governance, decision-making and co-production;
technical frameworks for open data and metadata (e.g. ontologies, data formats, standards and APIs; data visualization; data quality);
evidence and impacts of open data: on society and/or public administration; value of real-life applications based on open data, costs and benefits of providing or using open data; emerging good practices; value generation (e.g. transparency, accountability, economic value, public service provision).
Data sharing and use, including but not limited to:
data with different levels of openness;
the role of public, private and societal stakeholders in data sharing and use, data end-users and intermediaries;
challenges and solutions for data sharing and use by various actors, including governments, researchers, companies, citizens, journalists, students, NGOs, librarians and intermediaries.
Open science, open access and open source software, including but not limited to:
best practices of open science;
benefits and challenges of scholarly publication, publishing data, information, articles and code through portals and platforms with different levels of openness;
safe and responsible sharing of data, information, articles and code with others
communication platforms to get more exposure and enhance usability of (open) data information, publications and code.
We encourage a diversity of methods and theoretical lenses, including critical studies in the above-mentioned thematic fields. It is the journal’s mission to encourage interdisciplinarity, unconventional ideas and multiple perspectives, and to connect leading thinkers and young scholars in inspiring reflections. JeDEM is an innovative journal that welcomes submissions from all disciplines and approaches. We publish both theoretical and empirical research, both qualitative and quantitative.
For the types of contribution, they are:
Research papers (double blind peer-review):
Regular submissions (submitted throughout the year, unrelated to a specific call for papers);
Special issue submissions (related to a call for papers);
JeDEM provides full open access to its authors and readers. Publishing with and reading JeDEM is free of charge. We ask authors to register with JeDEM to manage the publishing process. To gain all the benefits of the JeDEM community we recommend authors, readers, editors and reviewers to register their interest with JeDEM. JeDEM is a peer-reviewed, open-access journal (ISSN: 2075-9517). All journal content, except where otherwise noted, is licensed under the Creative Commons Attribution Licence.