
The very last days of the year give us all time to reflect on what the past year has brought us. This years and these very last days of it are no exception. As usually, I will skip the part about pains and tears and try to focus only on positive things, because at the end of the day, “that which does not kill us makes us stronger” (Friedrich Nietzsche). Otherwise, this year has been full of a lot of different events and experiences, so I indeed want to take a moment and summarize what has so little time for some things (actually, not because you are lazy – as I often think of myself (a moment when people who know me well can laugh a little), but because you were busy with other things you gave you preference / priority over others).

So, how has 2023 been or what am I grateful for?
First of all, given the amount of emotion they bring, I am grateful for all those conferences I attended this year, serving as both – a part of the organizing committee, the program committee, the chair – chairing my (co-)organized workshops, the track (co-)chair, the speaker – presenting my works, or even serving as a keynote & invited speaker, as well as a plenary speaker and taking part in the “meet the publisher” session as a representative (Area Editor) of the journal. In total, I attended 13 international conferences (some of which I attended virtually), with some more events of a more national and/or regional nature.
Let me start with the role of keynote speaker, as I finally added another continent to “my list” of keynotes this year. Surprisingly, it was Europe. In other words, in previous years I have already served as a keynote or invited speaker at events in Latin America, Asia, Africa, but this year I gave 4 more talks in Asia and finally in Europe – 3 keynote talks / invited talks 🙂 (not to say how cool I am, but rather to express my gratitude to those who invite me to deliver keynote talks, despite my relatively young age but being interested in the content I deliver).
Moreover, I had the pleasure of covering all those topics that I love and deal (or dealt) with, namely public/ open data ecosystems, data quality management, information systems / data security, and intersection of artificial intelligence, data intelligence and collaborative intelligence. Moreover, I had the exceptional pleasure of delivering them to very different audiences, where two talks were delivered to academic circles (CARMA2023 and DemocrAI as part of PRICAI), one – to participants of one of the leading hackathons in Europe (HackCodeX Forum), and one – to representatives of industry (CyberCommando’s meetup 2023):
- Keynote talk “Public data ecosystems in and for smart cities: how to make open / Big / smart / geo data ecosystems value-adding for SDG-compliant Smart Living and Society 5.0?” for the 5th International Conference on Advanced Research Methods and Analytics (CARMA2023) “Internet and Big Data in Economics and Social Sciences”, June 28-30, Seville, Spain (read more here, find slides here);
- Keynote talk “Unlocking the symbiotic relationship of Artificial Intelligence, Data Intelligence, and Collaborative Intelligence for Innovative Decision Making and Problem Solving“ for the 3rd International Workshop on Democracy & AI (DemocrAI) held in conjunction with 20th Pacific Rim International Conference on Artificial Intelligence (PRICAI), November 16, Jakarta, Indonesia (online, read more here);
- Keynote talk “Data Quality as a prerequisite for you business success: when should I start taking care of it?“ for HackCodeX Forum, June 5, Riga, Latvia (read more here, find slides here, watch it here);
- Invited talk CyberCommando’s meetup 2023 “What do Internet of Things Search Engines know about you? or IoTSE as a vulnerable open data sources detection too“, October 26, Riga, Latvia (read more here)
In addition, plenary debates within the Research and Innovation Forum 2023 “Innovation 5.0: Navigating shocks and crises in uncertain times Technology-Business-Society” (RiiForum2023): “Advances in ICT & the Society: threading the thin line between progress, development and mental health“, where I was kindly invited to take part as one of plenary speakers, is another wonderful experience worth mentioning, especially, when you are invited with the line stating that your “expertise and your contribution to the academic debate make you one of the trendsetters in current debate on open data and data quality management“. As part of this event, we – Prof. Dr. Yves Wautelet, Prof. Dr. Marek Krzystanek, Karolina Laurentowska & Prof. Marek Pawlicki – discussed disruptive technologies and their role in our professional lives in the past years, how they affected us and our colleagues, how they affect(ed) society and its specific groups, including their mental health, and general perception of technology, i.e. an enemy of humanity, or rather a friend and support, and how to make sure the second take place. And from this we have developed a discussion around AI, chatGPT, Metaverse, blockchain, even slightly touching on quantum computing. Of course, all this was placed in the context of democracy and freedoms / liberties. All in all, we approached the topic of governance and policy-making, which is too often reactive rather than proactive, which, in turn, leads to many negative consequences, as well as elaborated on the engineering practices. You can read about this here.









In addition, two international workshops were (co-)organized and chaired by me this year and took place as part of IFIP EGOV-CeDEM-EPART 2023 and dg.o 2023, namely:
- “PPPS’2023 – Proactive and Personalised Public Services: Searching for Meaningful Human Control in Algorithmic Government” workshop (chairs: Anastasija Nikiforova, Nitesh Bharosa, Dirk Draheim, Kuldar Taveter) as part of EGOV2023 – IFIP EGOV-CeDEM-EPART 2023, organizer and chair of , September 5-7, Budapest, Hungary (read more here)
- “Identification of high value dataset determinants: is there a silver bullet for efficient sustainability-oriented data-driven development?” workshop (chairs: Nikiforova A., Alexopoulos C., Rizun N., Ciesielska M.) as part of 24th Annual International Conference on Digital Government Research (dg.o 2023), Together in the unstable world: Digital government and solidarity, 11-14 July 2023, Gdańsk, Poland (read more here) – the third edition of this workshop.


The other role of session chair is particularly special as it allows you to actively participate in the discussion of all the works presented in those sessions, as well as to “drive” and “direct” the discussion established and developed by and with others participants. Therefore, I am often pleased to accept an invitation to chair sessions, and this year I did it for:
- EGOV2023 – IFIP EGOV-CeDEM-EPART 2023, “Emerging Issues and Innovations” track
- ICCNS2023 – The International Conference on Intelligent Computing, Communication, Networking and Services
- Research and Innovation Forum 2023 “Innovation 5.0: Navigating shocks and crises in uncertain times Technology-Business-Society”
- iMeta and FMEC 2023 – The International Conference on Intelligent Metaverse Technologies & Applications in conjunction with the The Eighth IEEE International Conference on Fog and Mobile Edge Computing (FMEC)
At some of these conferences, along with some others, I also serve as part of the program or even organizing committee, which allows me to be closer to the event itself, being involved in it as much as possible. This, of course, requires some efforts (at times a lot of them), but still it is a very valuable experience that allows to derive many valuable insights for developing yourself – for this opportunity this year I am grateful to all those 18 conferences that I managed to count (EGOV, AMCIS, iLRN2023 etc.), in which I have been involved in one or another capacity, taking one or another role that spans from publicity chair to steering committee member. Similarly, it is always a pleasure for me to serve as invited reviewer for high-quality journals (15+), as well as to serve as editor for some of them.
Of course, the above involves participation in these conferences as a speaker/ presenter, presenting your own papers. Therefore, the next point to mention and express my gratitude to both my colleagues – co-authors, reviewers, editors and many more, are those contributions that were published or born this year.














That is, several articles were published this year – 22 to be more precise, some of which were simply published in 2023, although they were written earlier (including my past collaboration with Quantum Humanities network, the Latvian Biomedical Research and Study Centre, BBMRI-ERIC Latvian National Node and others), 9 of which are journal papers (incl. both Government Information Quarterly – a top journal in public administration, social science and information science, and Nature-based European Journal of Human Genetics), 2 are book chapters, 8 – conference papers and 3 – whitepapers & reports, including those published by the European Commission (developed together with my colleagues from European Open Science Cloud (EOSC) Task Force “FAIR metrics and data quality”):
- Lnenicka, M., Nikiforova, A., Luterek, M., Milic, P., Rudmark, D., Neumaier, S., Santoro, C., Casiano Flores, C., Janssen, M., & Rodríguez Bolívar, M. P. (2024). Identifying patterns and recommendations of and for sustainable open data initiatives: A benchmarking-driven analysis of open government data initiatives among European countries. Government Information Quarterly, 41(1): 101898. https://doi.org/10.1016/j.giq.2023.101898, Q1, Impact Factor: 7.8
- Guerra-García, C., Nikiforova, A., Jiménez, S., Perez-Gonzalez, H. G., Ramírez-Torres, M., & Ontañon-García, L. (2023). ISO/IEC 25012-based methodology for managing data quality requirements in the development of information systems: Data quality by design. Data & Knowledge Engineering, 102152, https://doi.org/10.1016/j.datak.2023.102152, Q2, Impact Factor: 1.5, CiteScore: 4.9
- McBride, K., Nikiforova, A., and Lnenicka, M. (2023) ‘The Role of Open Government Data and Co-creation in Crisis Management: Initial Conceptual Propositions from the COVID-19 Pandemic’. Information Polity, 28(2), 219-238, http://dx.doi.org/10.3233/IP-220057, Q2, IF: 2.784, CiteScore: 4.4
- Ukpabi, D.C., Karjaluoto, H., Botticher, A., Nikiforova, A., Petrescu, D.I., Schindler, P., Valtenbergs, V., Lehmann, L., Framework for Understanding Quantum Computing Use Cases From A Multidisciplinary Perspective and Future Research Directions, Futures, 2023, 103277, ISSN 0016-3287, https://doi.org/10.1016/j.futures.2023.103277, Q1 in (1) Business and International Management, (2) Development, (3) Sociology and Political Science), IF:3, CiteScore: 6.3
- Shao, D., Ishengoma, F.R., Alexopoulos, C., Saxena, S., Nikiforova, A. and Matheus, R. (2023), “Integration of IoT into e-government”, Foresight, Vol. ahead-of-print No. ahead-of-print. https://doi.org/10.1108/FS-04-2022-0048, Q2 (Business and International Management, Economics, Econometrics and Finance), IF: 1.581, CiteScore: 3.1
- Chang, V., Marshall, R., Xu, Q. A., & Nikiforova, A. (2023). E-commerce assistant application incorporating machine learning image classification. International Journal of Business and Systems Research, 17(1), 1-26, https://doi.org/10.1504/IJBSR.2023.127711
- Kante N., Nikiforova A., Kaleja K., Svandere A., Mežinska S., Pečulis R., Rovite V. Dynamic informed consent system, citizen science data management, quality control and integration for Latvian Genome Database, Abstracts from the 55th European Society of Human Genetics (ESHG) Conference: Hybrid Posters. Eur J Hum Genet 31 (Suppl 1), 345–709 (2023). https://doi.org/10.1038/s41431-023-01338-4, Q1, IF:4.42
- Azeroual, O., Schöpfel, J., Pölönen, J., Nikiforova, A. (2023). FAIRification of CRIS: A Review. In: Coenen, F., et al. Knowledge Discovery, Knowledge Engineering and Knowledge Management. IC3K 2022. Communications in Computer and Information Science, vol 1842. Springer, Cham
- Chang V., Xiao L., Nikiforova A., Xu Q., Liu B. (2023) The Study of PGP Web of Trust Based on Social Network Analysis, International Journal of Business Information Systems, 44(2), pp.285-302, https://dx.doi.org/10.1504/IJBIS.2023.134956, SNIP: 0.551, CiteScore: 1.7 (Q2 – Information Systems and Management, Management Information Systems)
- Nikiforova, A. (2023). Open Data Hackathon as a Tool for Increased Engagement of Generation Z: To Hack or Not to Hack?. In: Ortiz-Rodríguez, F., Tiwari, S., Sicilia, MA., Nikiforova, A. (eds) Electronic Governance with Emerging Technologies. EGETC 2022. Communications in Computer and Information Science, Springer, Cham. https://doi.org/10.1007/978-3-031-22950-3_13
- Nikiforova, A., Rizun, N., Ciesielska, M., Alexopoulos, C., Miletić, A. (2023). Towards High-Value Datasets Determination for Data-Driven Development: A Systematic Literature Review. In: Lindgren, I., et al. Electronic Government. EGOV 2023. Lecture Notes in Computer Science, vol 14130. Springer, Cham. https://doi.org/10.1007/978-3-031-41138-0_14
- Nikiforova, A., Alexopoulos, C., Rizun, N., Ciesielska, M. (2023) Identification of High-Value Dataset determinants: is there a silver bullet for efficient sustainability-oriented data-driven development? In Proceedings of the 24th Annual International Conference on Digital Government Research (pp. 676-678), 10.1145/3598469.3598556
- Nikiforova, A., Draheim, D., Taveter, K., Bharosa, N. (2023). PPPS’2023 – Proactive and Personalised Public Services: Searching for Meaningful Human Control in Algorithmic Government. EGOV-CeDEM-ePart2023, September,5-7, 2023, Budapest, Hungary
- Azeroual O., Nacheva R., Nikiforova A., Störl U., Fraisse A. (2023) Predictive Analytics intelligent decision-making framework and testing it through sentiment analysis on Twitter data. In Proceedings of the 24th International Conference on Computer Systems and Technologies (CompSysTech ’23). Association for Computing Machinery, New York, NY, USA, 42–53. https://doi.org/10.1145/3606305.3606309
- O. Azeroual, A. Nikiforova and K. Sha, “Overlooked Aspects of Data Governance: Workflow Framework For Enterprise Data Deduplication,” 2023 International Conference on Intelligent Computing, Communication, Networking and Services (ICCNS), Valencia, Spain, 2023, pp. 65-73, http://dx.doi.org/10.1109/ICCNS58795.2023.10193478.
- Nikiforova, A. (2023). Data Security as a Top Priority in the Digital World: Preserve Data Value by Being Proactive and Thinking Security First. In: Visvizi, A., Troisi, O., Grimaldi, M. (eds) Research and Innovation Forum 2022. RIIFORUM 2022. Springer Proceedings in Complexity. Springer, Cham. https://doi.org/10.1007/978-3-031-19560-0_1
- Daase, C.; Staegemann, D.; Nikiforova, A.; Chang, V.; Hintsch, J.; Volk, M. and Turowski, K. (2023). Towards the Creation of a Holistic Video Analytics Platform for Retail Environments. In Proceedings of the 20th International Conference on Smart Business Technologies – ICSBT; ISBN 978-989-758-667-5; ISSN 2184-772X, SciTePress, pages 216-225. DOI: 10.5220/0012148600003552
- Nikiforova, A., Flores, M.A.A. and Lytras, M.D. (2023), “The Role of Open Data in Transforming the Society to Society 5.0: A Resource or a Tool for SDG-Compliant Smart Living?“, Lytras, M.D., Housawi, A.A. and Alsaywid, B.S. (Ed.) Smart Cities and Digital Transformation: Empowering Communities, Limitless Innovation, Sustainable Development and the Next Generation, Emerald Publishing Limited, Bingley, pp. 219-252. https://doi.org/10.1108/978-1-80455-994-920231011
- Nikiforova, A., Daskevics, A. and Azeroual, O. (2023), “NoSQL Security: Can My Data-driven Decision-making Be Influenced from Outside?“, Visvizi, A., Troisi, O. and Grimaldi, M. (Ed.) Big Data and Decision-Making: Applications and Uses in the Public and Private Sector (Emerald Studies in Politics and Technology), Emerald Publishing Limited, Bingley, pp. 59-73. https://doi.org/10.1108/978-1-80382-551-920231005
- Lacagnina, C., David, R., Nikiforova, A., Kuusniemi, M. E., Cappiello, C., Biehlmaier, O., Wright, L., Schubert, C., Bertino, A., Thiemann, H., & Dennis, R. (2023). Towards a data quality framework for EOSC. Zenodo. https://doi.org/10.5281/zenodo.7515816
- Wilkinson MD, Sansone SA, Méndez E., David R., Dennis R., Hecker D., Kleemola M., Lacagnina C., Nikiforova A., Castro L. (2023) Community-driven governance of FAIRness assessment: an open issue, an open discussion [version 2; peer review: 2 approved with reservations]. Open Res Europe 2023, 2:146 (https://doi.org/10.12688/openreseurope.15364.2)
- Bötticher A., Nikiforova A., Ruhland J., Kettemann M. (2023), Reframing Political Power in the Digital Constellation: Taking Technopolitics Seriously, Future Law Working Paper 2023-2, Department of Theory and Future of Law, University of Innsbruck, Austria
It also brought some recognition for which I am very grateful. To name just a few…
“ISO/IEC 25012-based methodology for managing data quality requirements in the development of information systems: Towards data quality by design” (César Guerra-García, Anastasija Nikiforova, Samantha Jiménez, Héctor G. Perez-Gonzalez, Marco Ramírez-Torres, Luis Ontañon-García) turned out to be interesting for the readership and since July 2023 (when I noticed this) holds in the list of the most downloaded articles from Data & Knowledge Engineering in the last 90 days, which, of course, makes us very happy (it would be great, however, to be in the most cited or better – influential -works :))
“Towards High-Value Datasets determination for data-driven development: a systematic literature review” (Nikiforova A., Rizun N., Ciesielska M., Alexopoulos C., Miletič A.) received a recommendation from The Living Library that seeks to provide actionable knowledge on governance innovation, informing and inspiring policymakers, practitioners, technologists, and researchers working at the intersection of governance, innovation, and technology in a timely, digestible and comprehensive manner, identifying the “signal in the noise” by curating research, best practices, points of view, new tools, and developments, has included it in their collection. This is already the second paper recommended by the Living Library (the first one was this paper) that is recommended by them, what makes me very proud – thanks a lot!
“The Role of Open Data in Transforming the Society to Society 5.0: A Resource or a Tool for SDG-Compliant Smart Living?“ (Nikiforova, Flores, Lytras), was recommended by FIT Academy as one of the “five outstanding articles about open data published by top experts from around the world” naming it to be “a groundbreaking research paper”, which was a very great surprise to us as authors.
According to ResearchGate calculated Interest Score, my score is higher than 99% of ResearchGate members who first published in the same year as me, namely, 2018, which, however, means that more globally, i.e., among all ResearchGate members my current Research Interest Score is higher than 90% of researchers registered in it – although there is a lot of room for improvement, I still find it to be something to be grateful for to all my colleagues with whose support this has been achieved.
Moreover, this year I was listed in the Stanford University database of top 2% scientists! I recognize that this is just a single year category for 2022, and it is about sub-fields (Artificial Intelligence, Information Systems, Information Communication Technologies) same as I realize that citation metrics-based evaluations is not the best approach to assessing the impact and quality of research & researcher (although this database not only acknowledges, but also tries to tackle this issue to some extent), but for me it is a real achievement that made this year special!



Here I would also like to acknowledge the achievements of others, since this year I also witnessed 4 PhD defenses, acting as both opponent, internal reviewer and defense committee, all of which were successful. Here, I would like to once again congratulate both new PhD holders, namely:
- Dr. Rozha K. Ahmed and her PhD thesis “Digital Transformation of Court Processes: Driving Forces, Success Factors, Regulations and Technology Acceptance” (TalTech – Tallinn University of Technology, TalTech School of IT) – read it here;
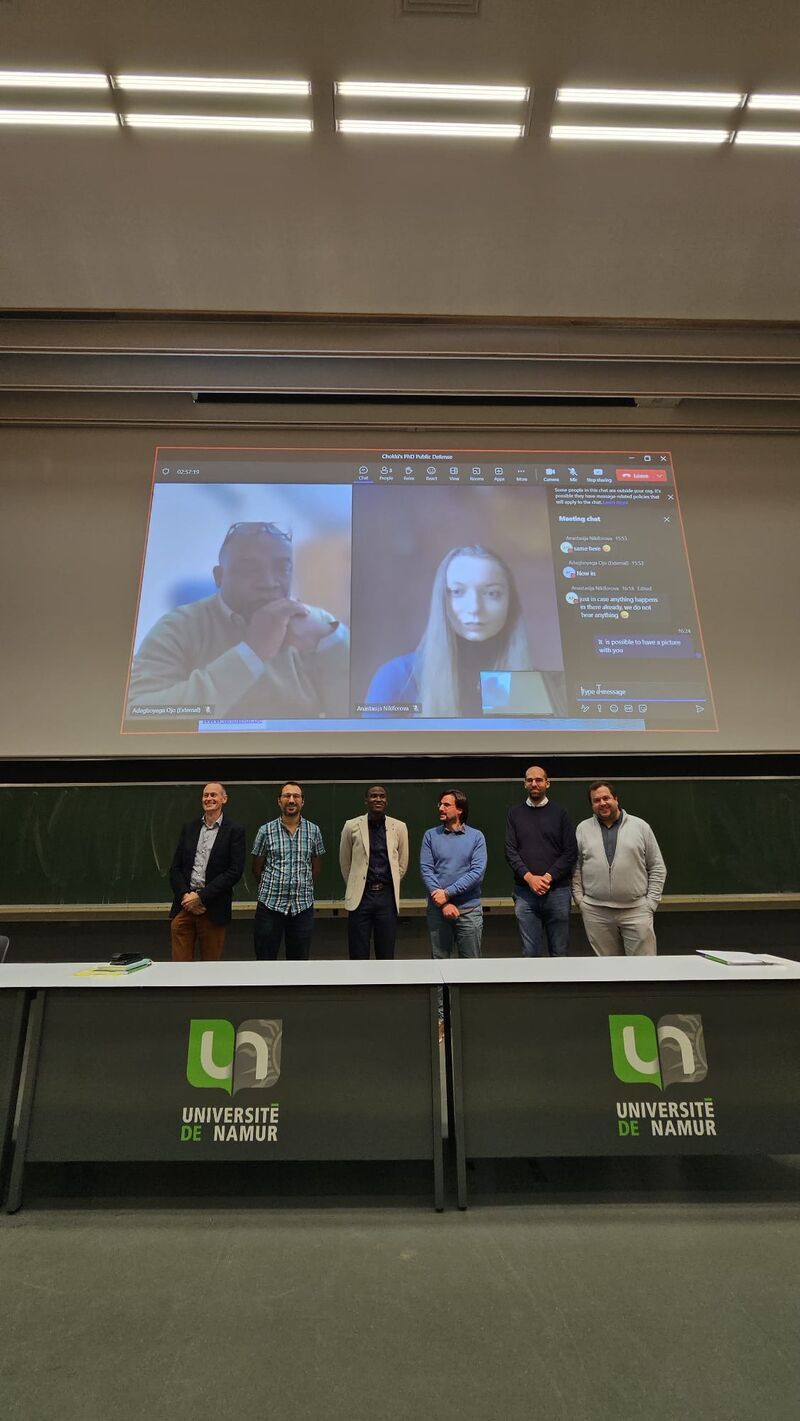
- Dr. Abiola Paterne Chokki and his PhD thesis “Open Government Data: Empowering Reuse through Collaboration, Data Quality, and Data Storytelling” (The University of Namur / Université de Namur) – read it here;
- Dr. Sidra Azmat Butt and her PhD thesis “A Digital Collaborative Platform to Facilitate Innovative Solutions for the Silver Economy” (TalTech – Tallinn University of Technology) – read it here;
- Dr. Abasi-amefon Affia, who has successfully defended her PhD thesis “A Framework and Teaching Approach for IoT Security Risk Management” (University of Tartu) – read it here;



But, of course, I tried not only to acquire new knowledge and develop new skills or improve existing ones, but also to share them with others – students – my own (Business Process Management, as well as Systems Modelling courses) and of my colleagues, colleagues, pupils, school teachers, industry and others. This year I had a few more opportunities to do this by:
- continuing collaboration with Latvian Open Technologies Association and serving as a mentor for Open Data hackathon and Idea Generator (this year focused on digital wallet) for pupils, organized by the Latvian Open Technologies Association with the support of Vides aizsardzības un reģionālās attīstības ministrija (VARAM)/ Ministry of Environmental Protection and Regional Development of Republic of Latvia, Latvijas Valsts radio un televīzijas centrs / Latvia State Radio and Television Centre, Valsts izglītības satura centrs / National Centre for Education of the Republic of Latvia, E-Klase, NOBID Consortium, Rīgas Tehniskā universitāte (Riga Technical University), European Commission and supporters – Omniva, ZZ Dats, Latvijas Banka/ The Bank of Latvia and others. This year the main topic of the hackathon was Digital Wallet for secure identification and wide service opportunities within Europe, as part of which dozens of pupils brought on the table great ideas on how the combination of open data and digital wallets can contribute to the development and improvement in such a different sectors, and improve lives of society – with healthcare, wellbeing, sustainability, ecology and simplification of processes as the main topics covered by participants (read a bit more here). This was my fourth hackathon in a row with LATA and it seems not the last;
- continuing collaboration with the “School of Excellence” (latv. Izcilības skola), organized by the “Vertikāle” Youth Foundation in cooperation with the University of Latvia (Latvijas Universitāte) for the most promising 10th-12th grade students / brightest minds, helping them make decision about their future career. In this invited lecture, we looked at several topics that they could connect they career with – computer science, information systems, software engineering, artificial intelligence, collaborative intelligence, data intelligence, data quality management, open data, open government data – I hope this will help them make a decision, and, hopefully in favor of IT! This was my third time participating in this series of lectures, and I was already unofficially invited to continue this “tradition”;
- continuing collaboration with Riga TechGirls as part of their exceptional program supported by Google.org (“Google Impact challenge” grant, in addition to local supporters such as the Ministry of Education and Science of Latvia, the Ministry of Culture, Riga city council (Rīgas Dome)), titled “Human on technology”, which is intended for more than 2000 Latvian teachers with the aim of disrupting technophobia and provide them with digital skills that are “must-have” in this digital world/ era, where in the last two years I have acted as both the lecturer and the lead mentor for the digital development workshop held as a part of the “Information and data literacy” module (read more…)
- continuing collaboration with both University of South-Eastern (Norway) and the Federal University of Technology – Paraná (UTFPR) (Brazil), serving as a guest lecturer for them – also the third year in a row for both of them. In the case of the University of South-Eastern Norway, these lectures are part of “Emerging Technologies in Information Systems“ course developed by Salah Uddin Ahmed, and this year my guest lecture was on Data Quality Management entitled “Data Quality for AI or AI for Data quality: advances in Data Quality Management for the success and sustainability of emerging technologies, business and society“, while in the case of the Federal University of Technology – Paraná (UTFPR), my lecture “Open Data Ecosystems in and for sustainable development of data-driven smart cities and Society 5.0“ is part of “Smart Cities” course delivered by Regina Negri Pagani;
- making a short research visit to the Université de Namur (Belgium), where I delivered a seminar on my past, current and future research activities, mainly focusing on two areas, namely Data Quality Management, and the open data-, open government data- and public data ecosystems- related topics, covering both technological and social aspects of the above, and their role in the context of Smart City, Society 5.0, sustainable development with the general title of the seminar “Data Ecosystems: from User Centered systems engineering to (open) data management for sustainable and smart living & society”. I was very surprised by a high attendance and very grateful to everyone who managed to find the time for this, especially those colleagues who brought some others – it was a great discussion of different viewpoints, which followed by the closed defense of Abiola Paterne Chokki that fit nicely this discussion as well!









Finally, several ongoing activities to be mentioned includes:
- “Sustainable Public and Open Data Ecosystems” track we (chairs: Anastasija Nikiforova, Anthony Simonofski, Anneke Zuiderwijk & Manuel Pedro Rodríguez Bolívar) launched as part of the Annual International Conference on Digital Government Research (dg.o2024) and awaits your submissions (read more here);
- “Emerging Issues and Innovations” Track (chairs: Anastasija Nikiforova, Marijn Janssen, Francesco Mureddu) is still part of EGOV2023 – IFIP EGOV-CeDEM-EPART and await your submissions (read more here)
- “Emerging Data- and Policy-driven Approaches for African Cities Challenges” Special Issue (Editors: Jérôme Chenal, Stéphane C. K. Tekouabou, El Arbi Allaoui Abdellaoui, Anastasija Nikiforova) as part of Data & Policy journal (Cambridge University Press) accepts submissions till 8 January, 2024



This is a very short list of the events that I wanted to emphasize, and therefore, a short list of what I am grateful for this year and all those who were or are part of it. Overall, it was a busy and eventful year, to which I grateful for all the positive experiences and opportunities to transfer existing knowledge and acquire new ones from all those events and people I met there. I hope the next year will be even better. And in this regard, I wish us all a peaceful, joyful and productive year, in which we can cooperate and collaborate exclusively with those we respect and want to work with!

Thank 2023 and bye! Welcome 2024! Happy 2024!



")




