In response to several requests, I finally completed the very first blog post on data quality management. In this post, I’ve mainly “set the scene” with the intention of publishing several more in-depth blog posts related to specific areas of my interest within data quality management, including but not limited to AI-augmented data quality management.
As for now, this post is focused primarily on my personal opinion (experience-based) what influences the choice of the data quality management approach (i.e., smth very similar to what I talked about at HackCodeX Forum I posted about earlier, and where the photo comes from).
Last week I had the pleasure of taking part in a Data Science Seminar titled “When, Why and How? The Importance of Business Intelligence“. In this seminar, organized by the Institute of Computer Science (University of Tartu) in cooperation with Swedbank, we (me, Mohammad Gharib, Jurgen Koitsalu, Igor Artemtsuk) discussed the importance of BI with some focus on data quality. More precisely, 2 of 4 talks were delivered by representatives of the University of Tartu and were more theoretical in nature, where we both decided to focus our talks on data quality (for my talk, however, this was not the main focus this time), while another two talks were delivered by representatives of Swedbank, mainly elaborating on BI – what it can give, what it already gives, how it is achieved and much more. These talks were followed by a panel moderated by prof. Marlon Dumas.
In a bit more detail…. In my presentation I talked about:
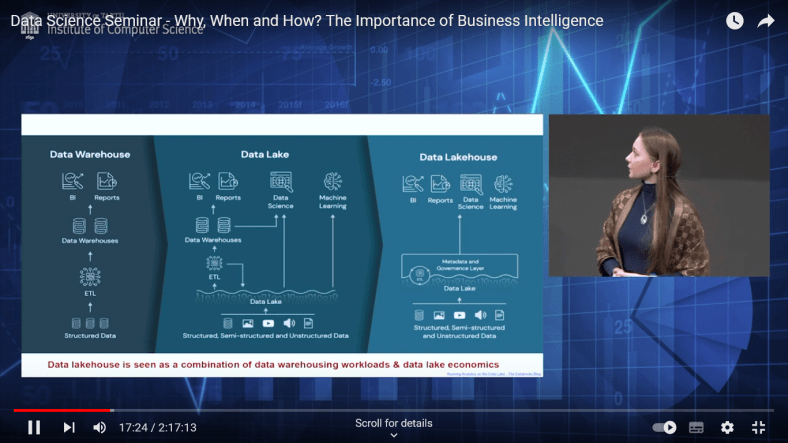
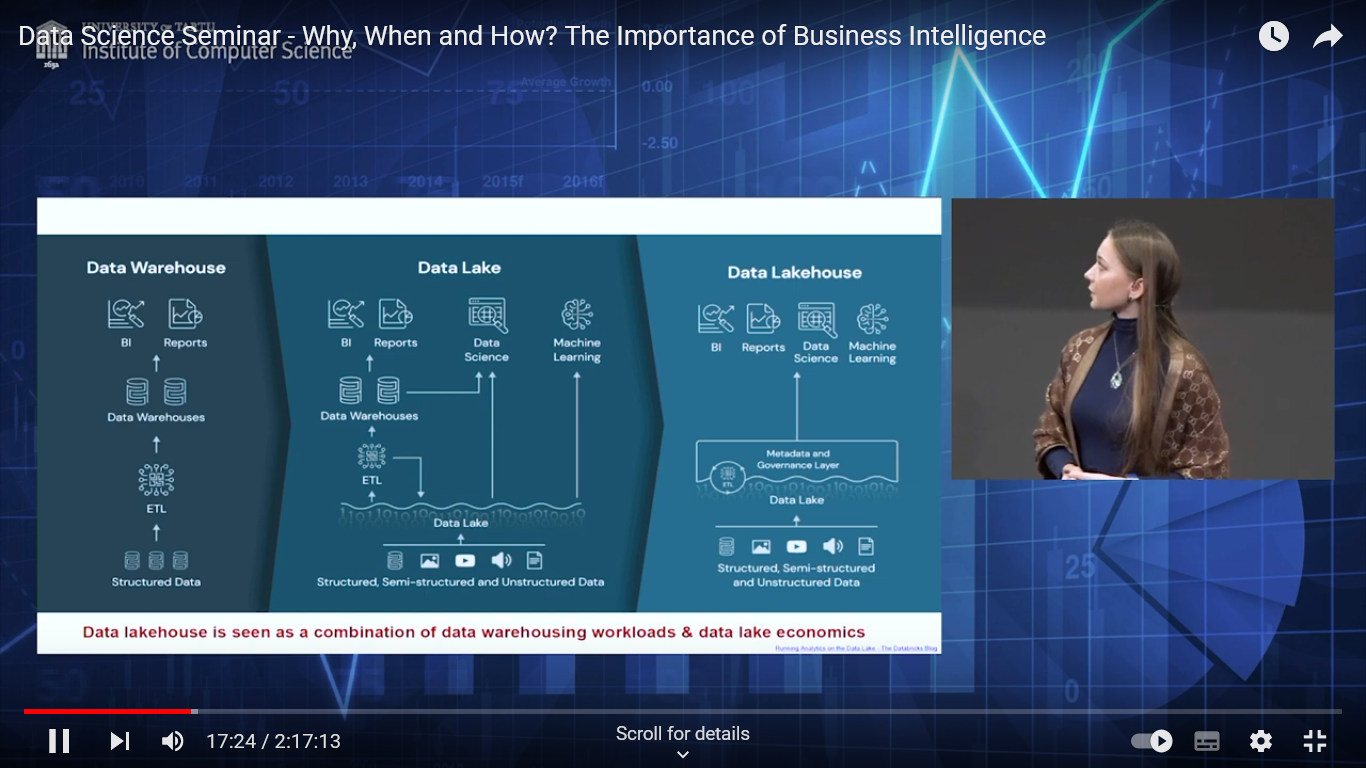
“Data warehouse vs. data lake – what are they and what is the difference between them?” – in a very few words – structured vs unstructured, static vs dynamic (real-time data), schema-on-write vs schema on-read, ETL vs ELT. With further elaboration on What are their goals and purposes? What is their target audience? What are their pros and cons?
“Is the Data warehouse the only data repository suitable for BI?” – no, (today) data lakes can also be suitable. And even more, both are considered the key to “a single version of the truth”. Although, if descriptive BI is the only purpose, it might still be better to stay within data warehouse. But, if you want to either have predictive BI or use your data for ML (or do not have a specific idea on how you want to use the data, but want to be able to explore your data effectively and efficiently), you know that a data warehouse might not be the best option.
“So, the data lake will save my resources a lot, because I do not have to worry about how to store /allocate the data – just put it in one storage and voila?!” – no, in this case your data lake will turn into a data swamp! And you are forgetting about the data quality you should (must!) be thinking of!
“But how do you prevent the data lake from becoming a data swamp?” – in short and simple terms – proper data governance & metadata management is the answer (but not as easy as it sounds – do not forget about your data engineer and be friendly with him [always… literally always :D) and also think about the culture in your organization.
“So, the use of a data warehouse is the key to high quality data?” – no, it is not! Having ETL do not guarantee the quality of your data (transform&load is not data quality management). Think about data quality regardless of the repository!
“Are data warehouses and data lakes the only options to consider or are we missing something?“– true! Data lakehouse!
“If a data lakehouse is a combination of benefits of a data warehouse and data lake, is it a silver bullet?“– no, it is not! This is another option (relatively immature) to consider that may be the best bit for you, but not a panacea. Dealing with data is not easy (still)…
In addition, in this talk I also briefly introduced the ongoing research into the integration of the data lake as a data repository and data wrangling seeking for an increased data quality in IS. In short, this is somewhat like an improved data lakehouse, where we emphasize the need of data governance and data wrangling to be integrated to really get the benefits that the data lakehouses promise (although we still call it a data lake, since a data lakehouse, although not a super new concept, is still debated a lot, including but not limited to, on the definition of such).
However, my colleague Mohamad Gharib discussed what DQ and more specifically data quality requirements, why they really matter, and provided a very interesting perspective of how to define high quality data, which further would serve as the basis for defining these requirements.
All in all, although we did not know each other before and had a very limited idea of what each of us will talk about, we all admitted that this seminar turned out to be very coherent, where we and our talks, respectively, complemented each other, extending some previously touched but not thoroughly elaborated points. This allowed us not only to make the seminar a success, but also to establish a very lively discussion (although the prevailing part of this discussion took place during the coffee break – as it usually happens – so, unfortunately, is not available in the recordings, the link to which is available below).