The Association for Information Systems (AIS) organized America’s Conference on Information Systems is coming! This year it will be held in Montreal (Canada), running under the general theme of “Intelligent technologies for a better future” and the revised list of (mini-)tracks, where the special attention I invite you to draw to is a new “Sustainable Digital and Data Ecosystems – Navigating the Age of AI” mini-track (chairs: Anastasija Nikiforova, Daniel Staegemann, George Marakas, Martin Lnenicka).
In an increasingly data-driven world, well-designed and managed digital and data ecosystems are critical to strategic innovation and competitive advantage. With the rise of new data architectures, the shift from centralized to decentralized systems, and the integration of artificial intelligence (AI) in data management, these ecosystems are becoming more dynamic, interconnected, and complex.
The growing importance of emerging data architectures such as data lakehouses and data meshes coupled with the emerging technologies of AI, blockchain, cloud computing to name a few, requires us to rethink how we manage, govern, and secure data across these ecosystems. Moreover, AI is no longer a mere component but an active agent/actor in these ecosystems, transforming processes such as data governance, data quality management, and security. Simultaneously, there is a pressing need to address how these systems can remain resilient and sustainable in the face of technological disruption and societal challenges, and how interdisciplinary approaches can provide new insights into managing these digital environments.
This mini-track seeks to explore the evolving nature of these ecosystems and their role in fostering sustainable, resilient, and innovative digital environments.
We encourage research from an ecosystem perspective (grounded in systems theory) that takes a holistic view, as well as more focused studies on specific components such as policies, strategies, interfaces, methodologies, or technologies. Special attention will be paid to the ongoing evolution of these ecosystems, especially their capacity to remain trustworthy, sustainable, and resilient over time.
Potential topics include but are not limited to:
data management and governance in emerging data architectures (data lakehouse, data mesh, etc.), including data governance, data quality management, and security;
the role of AI in data management, including AI-augmented governance, data quality management, and security;
AI-driven resilience and sustainability in digital and data ecosystems, incl. AI-augmentation of data lifecycle- and business- processes;
conceptualization and evolution of digital and data ecosystem components and their interrelationships;
emerging technologies, such as blockchain, cloud computing, sensors etc., shaping the strategic development of digital and data ecosystems;
case studies on the transition from centralized (data warehouse, data lake, data lakehouse) to decentralized data architectures (e.g., data mesh);
human/user factors in digital and data ecosystems (acceptance, interactions, participation etc.);
empirical studies on the sustainability, trustworthiness, and resilience of digital ecosystems;
methodologies and strategies for managing evolving digital ecosystems in different sectors (e.g., finance, healthcare, government / public sector, education).
interdisciplinary approaches to building, managing, and sustaining digital and data ecosystems.
The research and innovation in digital and data ecosystems requires an interdisciplinary approach. Therefore, this track invites papers from various disciplines such as information systems, computer science, management science, data science, decision science, organizational design, policy making, complexity, and behavioral economics, and social science to continue the problematization exploration of concepts, theories, models, and tools for building, managing and sustaining ecosystems. These can be conceptual, design science research, empirical studies, industry and government case studies, and theoretical papers, including literature reviews.
As such, this mini-track will serve as a platform for interdisciplinary dialogue on the critical role of sustainable digital and data ecosystems in driving strategic innovation and competitive advantage. We invite researchers and practitioners alike to share their insights, theoretical perspectives, and empirical findings in this rapidly evolving domain.
This mini-track is part of “Strategic & Competitive Uses of Information and Digital Technologies (SCUIDT)” track (chairs: Jack Becker, Russell Torres, Parisa Aasi, Vess Johnson).
For more information, see AMCIS2025 website (for this (min-)track, navigate to “Strategic & Competitive Uses of Information and Digital Technologies (SCUIDT)” track).
Is your research related to any of the above topics? Then do not wait – submit! 📅📅📅Submissions are due February 28, 2025.
October is Cybersecurity Awareness Month, as part of which CyberCommando’s meetup 2023 took place in the very heart of Latvia – Riga, where I was invited to deliver an invited talk that I devoted to IoTSE and entitled “What do Internet of Things Search Engines know about you? or IoTSE as a vulnerable open data sources detection tool“.
CyberCommando’s meetup organizers claim it to be the most anticipated vendor independent industry event in the realm of cybersecurity, a conference designed to empower our local and regional IT security professionals as we face the evolving challenges of the digital age by bringing together high-level ICT professionals from local, regional, and international businesses, governments and government agencies, tech communities, financial, public and critical infrastructure sectors. CyberCommando’s meetup covered a broad set of topics, starting from development of ICT security skills and Awareness Raising, to modern market developments and numerous technological solutions in the Cloud, Data, Mobility, Network, Application, Endpoint, Identity & Access, and SecOps, to corporate and government strategies and the future of the sector. Three parallel sessions and numerous talks delivered by 20+ local and international experts, including but not limited to IT-Harvest, Radware, DeepInstinct, Pentera, ForeScout Technologies, CERT.LV, ESET. It is a great honor to complement this list by the University of Tartu, which I represented delivering my talk at the main stage 🙂
Let’s refer to my talk – “What do Internet of Things Search Engines know about you? or IoTSE as a vulnerable open data sources detection tool“. Luckily, very few attendees knew or used OSINT (Open Source INTelligence), Internet of Things Search Engines (IoTSE) (however, perhaps they were just too shy to raise their hands when I asked this), so, hopefully, this was a good choice of topic. So, what was it about?
Today, there are billions of interconnected devices that form Cyber-Physical Systems (CPS), Internet of Things (IoT) and Industrial Internet of Things (IIoT) ecosystems. As the number of devices and systems in use and the volume and the value of data increases, the risks of security breaches increase as well.
As I discussed previously, this “has become even more relevant in terms of COVID-19 pandemic, when in addition to affecting the health, lives, and lifestyle of billions of citizens globally, making it even more digitized, it has had a significant impact on business [3]. This is especially the case because of challenges companies have faced in maintaining business continuity in this so-called “new normal”. However, in addition to those cybersecurity threats that are caused by changes directly related to the pandemic and its consequences, many previously known threats have become even more desirable targets for intruders, hackers. Every year millions of personal records become available online [4-6]. Lallie et al. [3] have compiled statistics on the current state of cybersecurity horizon during the pandemic, which clearly indicate a significant increase of such. As an example,Shi [7] reported a 600% increase in phishing attacks in March 2020, just a few months after the start of the pandemic, when some countries were not even affected. Miles [8], however, reported that in 2021, there was a record-breaking number of data compromises, where “the number of data compromises was up more than 68% when compared to 2020”, when LinkedIn was the most exploited brand in phishing attacks, followed by DHL, Google, Microsoft, FedEx, WhatsApp, Amazon, Maersk, AliExpress and Apple.”
And while Risk based security & Flashpoint (2021) [5] suggests that vulnerability landscape is returning to normal, , incl. but not limited due to various activities, such as #WashYourCyberHands INTERPOL capmaign and “vaccinate your organization” movements, another trigger closely related to cybersecurity that is now affecting the world is geopolitical upheaval. Additionally, according to Cybersecurity Ventures, by 2025, cybercrimewill cost the world economy around$10.5 trillion annually,increasing from $3 trillion in 2015. Moreover, we are at risk of what is called Cyber Apocalypse or Cyber Armageddon, as was discussed during World Economic Forum (and according to Forbes), which is very likely to happen in coming 2 years (hopefully, it will not).
According to Forbes, the key drivers for this are the ongoing digitization of society,behavioral changes due to COVID-19 pandemic,political instability such as wars,the global economic downturn, while WEF relate this to the fact that technology becomes more complex, in particular, breakthrough technologies such as AI (considering current state-of-the-art, I would stress the role of quantum computing here), where I would stress that this “complexity” is two-fold, i.e., technologies become more advanced, while at the same time – easier to use, including those that can be used to detect and expose vulnerabilities. At the same time, although society is being digitized, society tend to lack digital literacy, data literacy & security literacy.
Hence, when we ask what should be done to tackle associated issues, the answer is also multi-fold, where some recommendations being actively discussed, including Forbes and Accenture, are to “secure the core”, which, in turn, involves ensuring that security and resilience are built into every aspect of the organization, understanding that cybersecurity is not something that’s only discussed within the IT department but rather at all levels of organization, organizations need to address the skills shortage within the cybersecurity domain, and it should involve utilizing automation where possible
To put it simply:
(cyber)securitygovernance
digitalliteracy
cybersecurityisnot a one-timeevent, but a continuous process
automationwheneverpossible
«security first!» as a principleforallartifacts, processesandecosystem
preferably – «security-by-design» and «absolute security», which, of course, is rather an utopia, but still something we have to try to achieve (despite the fact we know it is impossible to achieve this level).
Or even simpler, as I typically say – “security to every home!”.
In the light of the above, i.e., “security first!” as a principle for all artifacts and the need to “secure the core” – are our data management systems always protected by default (i.e., secure-by-design)? While it can sound surprisingly and weird in 2023, but this is a fact that while various security protection mechanisms have been widely implemented, the concept of a “primitive” artifact such as a data management system seems to have been more neglected and the number of unprotected or insufficiently protected data sources is enormous. Recent research demonstrated that weak data and database protection in particular is one of the key security threats [4,6,9-11]. According to a list drawn up by Bekker [5] and Identity Force on major security breaches in 2020, a large number of data leaks occur due to unsecured databases. As an example:
Estee Lauder – 440 million customer records
Prestige Software hotel reservation platform – over 10 million hotel guests, including Expedia, Hotels.com, Booking.com, Agoda etc.
U.K-based Security Firm gained data ofAdobe, Twitter, Tumbler, LinkedIn etc. and users with a total of over 5 billion records
Marijuana Dispensaries – 85 000 medical patient and recreational user records
to name just a few… At times it is due to their (mis)configuration, at times – due to the vulnerabilities in products or services, where additional security mechanisms would be required. Sometimes, of course, this due to the very targeted attacks, where the remaining of this post will have limited value, but let’s rather focus on those very critical cases, which refer to the above, especially in the context of the above mentioned fact that recent advances in ICT decreased the level of complexity of searching for connected devices on the Internet and easy access to them even for novices due to the widespread popularity of step-by-step guides on how to use IoTSE – aka Internet of Everything (IoE) or Open Source Intelligence (OSINT) Search Engines such as Shodan, BinaryEdge, Censys, ZoomEye, Hunter, Greynoise, Shodan, Censys, IoTCrawler – to find and gain access to insufficiently protected webcams, routers, databases, refrigerators, power plants, and even wind turbines. As a result, OSINT was recognized to be one of the five major categories of CTI (Cyber Threat Intelligence )sources (at times more than five are named, but OSINT remain to be part of this X categories), along with Human Intelligence (HUMINT), Counter Intelligence, Internal Intelligence and Finished Intelligence (FINTEL).
While these tools may represent a security risk, they provide many positive and security-enhancing opportunities. They provide an overview on network security, i.e., devices connected to the Internet within the company, are useful for market research and adapting business strategies, allow to track the growing number of smart devices representing the IoT world, tracking ransomware – the number and nature of devices affected by it, and therefore allow to determine the appropriate actions to protect yourself in the light of current trends. However, almost every of these white hat-oriented objectives can be exploited by black-hatters.
In this talk I raised several questions that can be at least partly answered with the help of IoTSE, such as:
Whether data source is visible and even accessible outside the organization?
What data can be gathered from it? and what is their “value” for external actors, such as attackers and fraudsters? I.e., whether these data can pose a threat to the organization using them to deploy an attack?
Are stronger security mechanisms needed? Is the vulnerability related to internal (mis)configuration or database in use?
To answer the above questions, I referred to the study that has been conducted by me and my former student – Artjoms Daškevičs (very talented student, whose bachelor thesis was even nominated to the best Computer Science thesis of in Latvia) some time ago. As part of that study an Internet of Things Search Engines- (IoTSE-) based tool called ShoBEVODSDT (Shodan- and Binary Edge-based Vulnerable Open Data Sources Detection Tool) was developed. This “toy example” of IoTSE conducts the passive assessment – it does not harm the databases but rather checks for potentially existing bottlenecks or weaknesses which, if the attack would take place, could be exposed. It allows for both comprehensive analysis for all unprotected data sources falling into the list of predefined data sources – MySQL, PostgreSQL, MongoDB, Redis, Elasticsearch, CouchDB, Cassandra and Memcached, or to define IP range to examine what can be seen from the outside of the organization about the data source (read more in (Daskevics and Nikiforova, 2021)).
The remainder was mostly built around four questions (and articles / book chapters) that we addressed with its help, namely:
Which data sources have proven to be the most vulnerable and visible outside the organization?
What data can be gathered from open data sources (if any), and what is their “value” for external actors, such as attacker and fraudsters? Whether these data can pose a threat to the organization using them to deploy an attack?
This part was built around our conference paper and this book chapter. In short (for a bit longer answer refer to the article), the number of data sources accessible outside the organization isless than 2% (more than 98% of data sources are not accessible via a simple IoTSE tool). However, there are some data sources that may pose risks to organizations and 12% of open data sources – data sources IoTSE tool was able to reach were already compromised or contain the data that can be used to compromise them. ElasticSearch and Memcached had the highest ratio of instances to which it was possible to connect, while MongoDB, PostgreSQL and ElasticSearch demonstrate the most negative trend in terms of already compromised databases (not by us, of course).
In addition, we might be interested in comparing SQL and NoSQL databases, where the latter are less likely to provide security measures, including sometimes very primitive and simple measures such as an authentication,authorization (Sahafizadeh et al., 2015) and data encryption. This is what we explored in the book chapter. We were not able to find significant differences, where from the “most secure”service viewpoint, CouchDB has demonstrated very good results in the context of security as the NoSQL database and MySQL as a relational database. However, if the developer needs to use Redis or Memcached, additional security mechanisms and/ or activities should be introduced to protect them. It must be understood, however, that these results cannot be broadly disseminated with regard to the security of the open data storage facility, mostly by demonstrating how many data storage holders were concerned about the security of their data storage facilities, since many data storage facilities have the potential to apply a series of built-in mechanisms. For the “most unsecure” service, Elasticsearch is characterized by weaker and less frequently used security protection mechanisms. This means that the database holder should be wary of using it. Similar conclusion can be drawn on Memcached (although it contradicts to CVE Details), where the total number of vulnerabilities found was the highest.However, the risk of these vulnerabilities was lower compared to ElasticSearch, so it can be assumed that CVE Details either does not respect such “low-level” weaknesses or have not yet identified them. Here in the future, an in-depth analysis of what CVE Details counts as vulnerability, and further exploration of the correlation with our results, could be carried out.
The next question we were interested in was:
Which Baltic country – Latvia, Lithuania, Estonia, has the most open & vulnerable data sources? and whether technological development of Estonia will be visible here as well?
This question was raised and partially answered in another conference paper. It is impossible to give an unambiguous answer here, since while Latvia showed the highest ratio of successful connections (and Estonia the lowest), Lithuania showed the most negative result in terms of already compromised data sources, and Estonia – for sensitive and non-sensitive data. Estonia, however, had the largest number of data sources from which data could not be obtained (with Latvia having a slightly lower but still relatively good result in this regard). And based on the average value of the data that could be obtained form these data sources, Lithuania again demonstrated the most negative result, which, however, was only slightly different from the result demonstrated by Estonia and Latvia (which may be a statistical error, since the total number of data sources found by our tool, differed significantly for these countries). When examining specific data sources that are more likely causing lower results, they vary from one country to another, so it is impossible to find the most insecure database that is the root of all problems.
And one more question I raised was:
Do “traditional” vulnerability registries provide a sufficiently comprehensive view of the DBMS security, or should they be subject for intensive and dynamic inspection by DBMS owners?
This was covered in the book chapter, which provides a comparative analysis of the results extracted from the CVE database with the results obtained as a result of the application of the IoTSE-based tool. It is not surprising – the results in most cases are rather complimentary, and one source cannot completely replace the second. This is not only due to scope limitations of both sources – CVE Details cover some databases not covered by ShobeVODSDT, as well as provide insights on more diverse set of vulnerabilities, while not providing the most up-to-date information with a very limited insight on MySQL. At the same time, there are cases when both sources refer to a security-related issue and their frequency, which can be seen as a trend and treated by users respectively taking action to secure the database that definitely do not comply with the “secure by design” principle. This refers to MongoDB, PostgreSQL and Redis.
All in all, it can be said that the answers to some of those questions may seem obvious or expected, however, as our research has shown, firstly, not all of them are obvious to everyone (i.e., there are no secure-by-design databases/data sources, so the data source owner has to think about its security), and, secondly, not all of these “obvious” answers are 100% correct.
All in all, both the talk and these studies show an obvious reality, which, however, is not always visible to the company. While “this may seem surprisingly in light of current advances, the first step that still needs to be taken thinking about date security is to make sure that the database uses the basic security features […] Ignorance or non-awareness can have serious consequences leading to data leakages if these vulnerabilities are exploited. Data security and appropriate database configuration is not only about NoSQL, which is typically considered to be much less secured, but also about RDBMS. This study has shown that RDBMS are also relatively inferior to various types of vulnerabilities. Moreover, there is no “secure by design” database, which is not surprising since absolute security is known to be impossible. However, this does not mean that actions should not be taken to improve it. More precisely, it should be a continuous process consisting of a set of interrelated steps, sometimes referred to as “reveal-prioritize-remediate”. It should be noted that 85% of breaches in 2021 were due to a human factor, with social engineering recognized as the most popular pattern [12]. The reason for this is that even in the case of highly developed and mature data and system protection mechanism (e.g., IDS), the human factor remains very difficult to control. Therefore, education and training of system users regarding digital literacy, as well as the definition, implementation and maintaining security policies and risk management strategy, must complement technical advances.“
Or, to put it even simpler, once again: digital literacy “to every home”, cybersecurity is not a one-time event but a continuous process, automation whenever possible, cybersecurity governance, “security first!” principle for all artifacts, processes and ecosystem, and, preferably, “security-by-design” principle whenever and wherever possible. Or, as I concluded the talk – “We have got to start locking that door!” (by Ross, F.R.I.E.N.D.S) before we act as Commando
Big thanks goes to the organizers of the event, esp. to Andris Soroka and sponsors, who supported such a wonderful event – HeadTechnology, ForeScout, LogPoint, DeepInstinct, IT-Harvest, Pentera, GTB Technologies, Stellar Cyber, Appgate, OneSpan, ESET Digital Security, Veriato, Radware, Riseba, Ministry of Defence of Latvia, CERT.LV, Latvijas Sertificēto Persona Datu Aizsardzības Speciālistu Asociācija, Dati Group, Latvijas Kiberpshiloģijas Asociācija, Optimcom, Vidzeme University of Appliced Sciences, Stallion, ITEksperts, Kingston Technology.
P.S. If, considering the topics I typically cover, you are wondering, why I am talking about security this time, let me briefly answer your question. First, for those who knows me better, it is a well-known fact that cybersecurity was my first choice in a big IT world – it was, is and probably remain my passion, although now it is rather a hobby. This was also the central part of my duties in one of my previous workplaces, incl. the one when I worked with the organizer of this event (oh my first honeypot…). Second, but related to the first point, this was the topic, addressing which one of my professors (during the first or the second year of my studies) told me that I must become a researcher (“yes, sure 😀 😀 😀 you must be kidding” was my thought at that point, but I do not laugh on this “ridiculous joke” anymore, and am rather grateful that I was noticed so early and was then constantly reminded about this by other colleagues, which resulted in the current version of me). Third, data quality and open data that I am talking about a lot are all about the value of the data, while two main prerequisites for this are (1) data quality and (2) data security, so, in fact, data security is inevitable component that we must think and talk about.
[3] Lallie, H. S., Shepherd, L. A., Nurse, J. R., Erola, A., Epiphaniou, G., Maple, C., & Belle-kens, X. (2021). Cyber security in the age of COVID-19: A timeline and analysis of cyber-crime and cyber-attacks during the pandemic. Computers & Security, 105, 102248.
[9] Daskevics, A., & Nikiforova, A. (2021, November). ShoBeVODSDT: Shodan and Binary Edge based vulnerable open data sources detection tool or what Internet of Things Search Engines know about you. In 2021 Second International Conference on Intelligent Data Sci-ence Technologies and Applications (IDSTA) (pp. 38-45). IEEE
[10] Li, L., Qian, K., Chen, Q., Hasan, R., & Shao, G. (2016, September). Developing hands-on labware for emerging database security. In Proceedings of the 17th Annual Conference on Information Technology Education (pp. 60-64)
[11] Fahd, K., Venkatraman, S., & Hammeed, F. K. (2019). A comparative study of NoSQL sys-tem vulnerabilities with big data. International Journal of Managing Information Technology, 11(4), 1-19
[6] E. Bekker (2020). Identity Force, A sontiq Brand. 2020 data breaches. The most significant breaches of the year.
Sahafizadeh, E., & Nematbakhsh, M. A. (2015). A survey on security issues in Big Data and NoSQL. Advances in Computer Science: an International Journal, 4(4), 68-72.
Considering that in last weeks I was pretty active in delivering very many talks, let me use this post to summarize some of them thereby remaining them in my memory as well as allowing you, my dear reader, to pick up some ideas or navigate to some projects (both projects, initiatives, postgraduate programs, joint workshops or “lunchs” for business and academia) of your interest. So this post is less about self-advertisement and my role in the below discussed events as both panelist, keynote, guest lecturer, invited speaker and expert, but more about very interesting projects, initiatives and labs currently running in different countries and at different scales – local, national, regional and international. And as “thank you” for the organizers of each of them, I would like to shed a light on them in this post, drawing your attention to them!
All in all, this post is about participating as a panelist for One Conference 2022, keynote for African Smart Cities Lab projects’ workshop (Morocco, Ghana, Tunisia, South Africa, Rwanda, Benin, Switzerland), Guest Lecture for master and doctoral students of the Federal University of Technology – Paraná (UTFPR, Postgraduate Program in Production Engineering, Brasil), and invited speaker / expert for monthly “Virtual Brown Bag Lunch” (Mexico), and EFSA & EBTC joint project (Italy) on the creation of a standard for data exchange in support of automation of Systematic Review.
So, let’s start with the most spontaneous, namely “Integration of open data and artificial intelligence in the development of smart cities in Africa” workshop organized as part of the African Cities Lab Project, where I was invited as a keynote speaker. Actually, African Smart Cities Lab project is a very interesting initiative I recently was glad to get familiar with. It is a joint initiative led by École polytechnique fédérale de Lausanne (Switzerland), the Kwame Nkrumah’ University of Science and Technology, Kumasi (Ghana), the UM6P – Mohammed VI Polytechnic University (Maroc), Sèmè City campus (Benin), the Faculty of Sciences of Bizerta – University of Carthage (Tunisia), the University of Cape Town (South Africa), and the University of Rwanda that aims to create a digital education platform on urban development in Africa, offering quality MOOC and online, continuing education training for professionals. It is also expected to act as a forum for the exchange of digital educational resources and the management and governance of African cities to foster sustainable urban development. The very first workshop took place July 5 in an online mode, where 9 speakers were invited to share their experience on this topic and allow setting the scene for the development of African Smart Cities, considering their potential, but also some bottlenecks.
All in all, two very fruitful sessions with presentations delivered by me, Vitor Pessoa Colombo, Constant Cap, Oualid Ali, Jérôme Chenal, Nesrine Chehata, AKDIM Tariq, Christelle Gracia Gbado, Willy Franck Sob took place and raised a lot of questions, finding the answers for many of them. My talk was titled “Open data and crowdsourced data as enablers and drivers for smart African cities” (see slides below…)
Here, let me immediately mention another activity – a Guest Lecture “The role of open data in the development of sustainable smart cities and smart society“, I delivered to students of the Federal University of Technology – Parana (UTFPR, Brazil) and, more precisely so-called PPGEP program – Postgraduate Program in Production Engineering (port. Programa de Pós-Graduação em Engenharia de Produção), in scope of which I was pleasured to raise a discussion on three topics of particular interest – open data, Smart City, and Society 5.0, which are actually very interrelated. This also allowed me to refer to one of our recent studies – Transparency of open data ecosystems in smart cities: definition and assessment of the maturity of transparency in 22 smart cities– published together with my colleagues – Martin Lnenicka, Mariusz Luterek, Otmane Azeroual, Dandison Ukpabi, Visvadis Valtenbergs, and Renata Machova in Sustainable Cities and Society (Q1, Impact Factor: 7.587, SNIP: 2.347, CiteScore: 10.7).
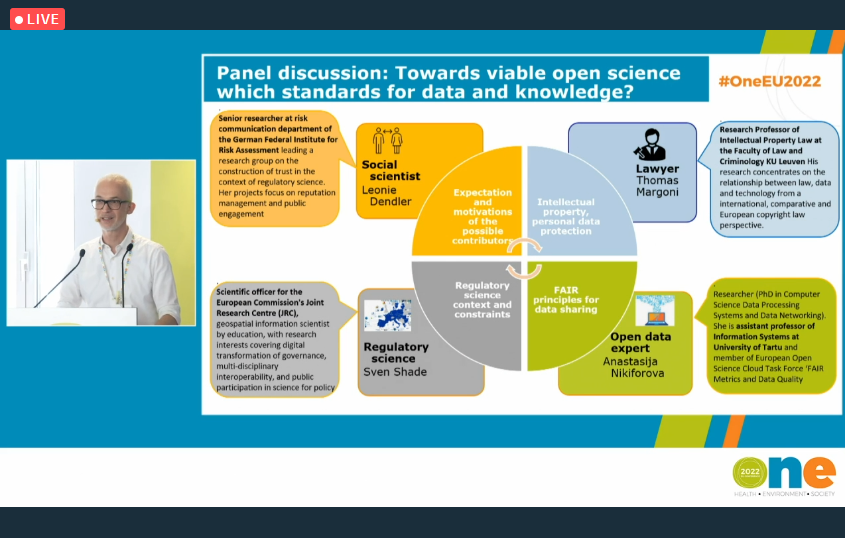
And now, it’s time to turn to two events organized by European Food Safety Authority (EFSA). The first and probably the most “crowded” due to a very high rate of the attendance was the ONE Conference 2022 (Health, Environment, Society), which took place between June 21 and 24, Brussels, Belgium. It was co-organised by European Food Safety Authority (EFSA) and its European sister agencies European Environment Agency, European Medicines Agency, European Chemicals Agency, European Centre for Disease Prevention and Control (ECDC), but if you are an active follower of my blog, you know this already, same as probably remember that I posted about this event previously inviting you to join us in Belgium or online. Since I have elaborated on the course of the event, its main objectives and tracks, I will not repeat this information. Instead, let me briefly summarize key takeaways with a particular focus on the panel for which I served as a panelist – the “ONE society” thematic track, panel discussion“Turning open science into practice: causality as a showcase”. It was a very nice experience and opportunity for sharing our experience on obstacles, benefits and the feasibility of adopting open science approaches, and elaborate on the following questions (although they were more but these one are my favorites): 💡Can the use of open science increase trust to regulatory science? Or does it increase the risk to lose focus, introduce conflicting interests and, thus, threaten reputation? What are the barriers to make open science viable in support to the scientific assessment process carried out by public organizations? 💡What are the tools/ methods available enabling, supporting and sustaining long term open science initiatives today and what could be envisaged for the future? 💡Do we need a governance to handle open data in support to scientific assessment processes carried out by regulatory science bodies? 💡How the data coming from different sources can be harmonized making it appropriate for further use and combination?
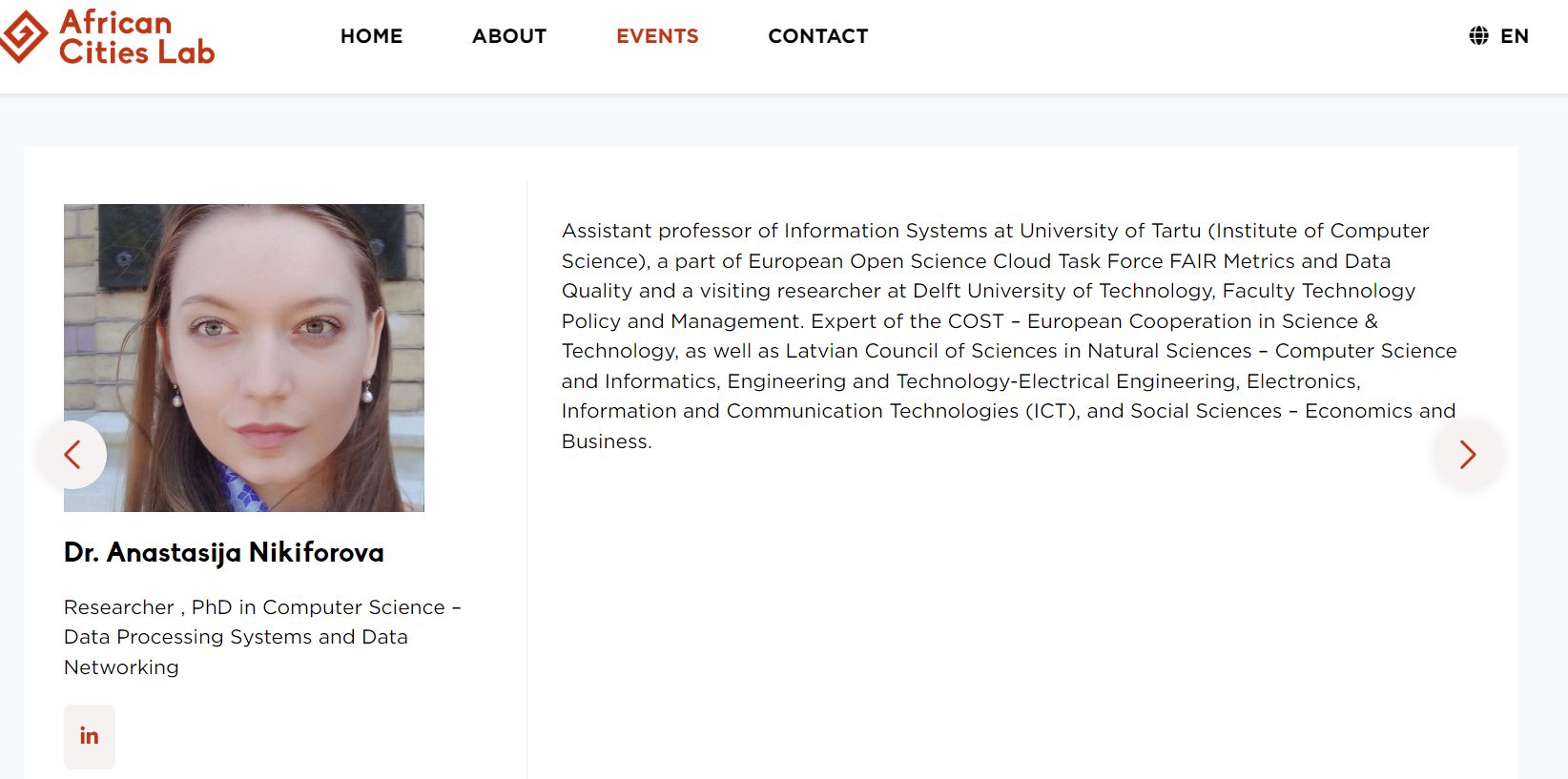
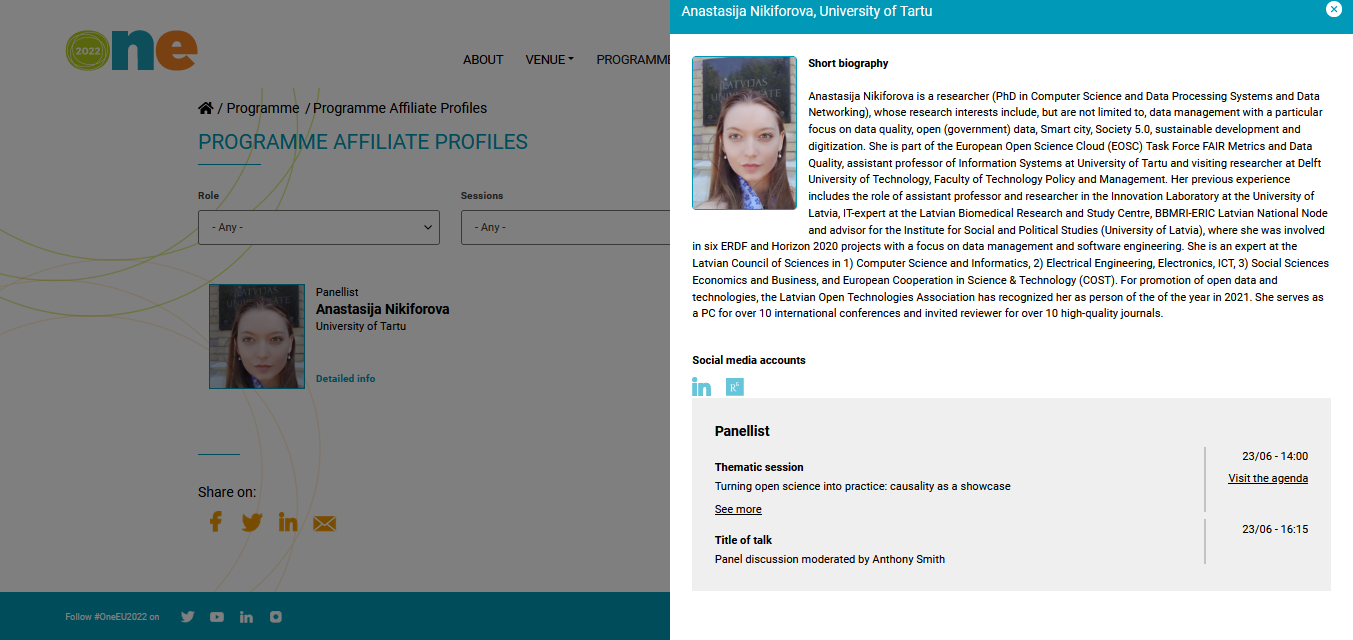
These and many more questions were discussed by panelists with different background and expertise, which were nicely presented by European Food Safety Authority (EFSA) breaking down our experience in four categories – social science (Leonie Dendler, German Federal Institute for Risk Assessment BfR), open data expert (Anastasija Nikiforova,) EOSC Association, University of Tartu, Institute of Computer Science, lawyer (Thomas Margoni, KU Leuven ), regulatory science (Sven Schade, Joint Research Centre, EU Science, Research and Innovation). Many thanks Laura Martino, Federica Barrucci, Claudia Cascio, Laura Ciccolallo, Marios Georgiadis, Giovanni Iacono, Yannick Spill (European Food Safety Authority (EFSA)), and of course to Tony Smith and Jean-François Dechamp (European Commission). For more information, refer to this page.
And as a follow-up for this event, I was kindly invited by EFSA to contribute to setting the scene on the concept of ‘standards for data exchange’, ‘standards for data content’ and ‘standards for data generation’ as part of European Food Safety Authority (EFSA) and Evidence-Based Toxicology Collaboration (EBTC) ongoing project on thecreation of a standard for data exchange in support of automation of Systematic Review (as the answer to the call made in “Roadmap for actions on artificial intelligence for evidence management in risk assessment”). It was really nice to know that what we are doing in EOSC Association (Task Force “FAIR metrics and data quality”) is of interest for our colleagues from EFSA and EBTC. Also, it was super nice to listen other points of view and get involved in the discussion with other speakers and organisers – Elisa Aiassa, Angelo Cafaro, Fulvio Barizzone, Ermanno Cavalli, Marios Georgiadis, Irene Pilar, Irene Muñoz Guajardo, Federica Barrucci, Daniela Tomcikova, Carsten Behring, Irene Da Costa, Raquel Costa, Maeve Cushen, Laura Martino, Yannick Spill, Davide Arcella, Valeria Ercolano, Vittoria Flamini, Kim Wever, Gunn Vist, Annette Bitsch, Daniele Wikoff, Carlijn Hooijmans, Sebastian Hoffmann, Seneca Fitch, Paul Whaley, Katya Tsaioun, Alexandra Bannach-Brown, Ashley Elizabeth Muller, Anne Thessen, Julie McMurray, Brian Alper, Khalid Shahin, Bryn Rhodes, Kaitlyn Hair. The next workshop is expected to take place in September with the first draft ready by the end of this year and presented during one of the upcoming events. More info on this will follow 🙂
In addition, I was asked by my Mexican colleagues to deliver an invited talk for monthly “Virtual Brown Bag Lunch Talks” intended for the Information Technologies, Manufacturing, and Engineering Employees in Companies associated with Index Manufacturing Association (Mexico, web-based). After discussing several topics with the organizers of this event, we decided that this time the most relevant talk for the audience would be “Data Security as a top priority or what Internet of Things (IoT) Search engines know about you“. Again, if you are an active follower, you will probably realize quickly that it is based on a list of my previous studies – study#1, study#2, study#3 and book chapter.
Certificates from Universidad Autononma de Tamaulipas & Index (Mexico) and Universidad Techlogica Federal de Parana (Brasil)
All in all, while these were just a few activities I was busy with during the last weeks and, these weeks were indeed very busy but extreeeemely interesting with so many different events! I am grateful to all those people, who invited me to take part in them and believe that this is just one of the opportunities we had to collaborate and there are many more in the future!
As I wrote earlier, this year I was invited to organize my own panel session within the Research and Innovation Forum (Rii Forum). This invitation was a follow-up on several articles that I have recently published (article#1, article#2, article#3) and a Chapter to be published in “Big data & decision-making: how big data is relevant across fields and domains” (Emerald Studies in Politics and Technology) I was developing at that time. I was glad to accept this invitation, but I did not even think about how many roles I will act in Rii Forum and how many emotions I will experience. So, how was it?
My own talk was titled “Data security as a top priority in the digital world: preserve data value by being proactive and thinking security first“, which makes it to be a part of the panel described above. In this talk I elaborated on the main idea of the panel, referring to an a study I recently conducted. In short, today, in the age of information and Industry 4.0, billions of data sources, including but not limited to interconnected devices (sensors, monitoring devices) forming Cyber-Physical Systems (CPS) and the Internet of Things (IoT) ecosystem, continuously generate, collect, process, and exchange data. With the rapid increase in the number of devices and information systems in use, the amount of data is increasing. Moreover, due to the digitization and variety of data being continuously produced and processed with a reference to Big Data, their value, is also growing. As a result, the risk of security breaches and data leaks. The value of data, however, is dependent on several factors, where data quality and data security that can affect the data quality if the data are accessed and corrupted, are the most vital. Data serve as the basis for decision-making, input for models, forecasts, simulations etc., which can be of high strategical and commercial / business value. This has become even more relevant in terms of COVID-19 pandemic, when in addition to affecting the health, lives, and lifestyle of billions of citizens globally, making it even more digitized, it has had a significant impact on business. This is especially the case because of challenges companies have faced in maintaining business continuity in this so-called “new normal”. However, in addition to those cybersecurity threats that are caused by changes directly related to the pandemic and its consequences, many previously known threats have become even more desirable targets for intruders, hackers. Every year millions of personal records become available online. Moreover, the popularity of IoTSE decreased a level of complexity of searching for connected devices on the internet and easy access even for novices due to the widespread popularity of step-by-step guides on how to use IoT search engine to find and gain access if insufficiently protected to webcams, routers, databases and other artifacts. A recent research demonstrated that weak data and database protection in particular is one of the key security threats. Various measures can be taken to address the issue. The aim of the study to which this presentation refers is to examine whether “traditional” vulnerability registries provide a sufficiently comprehensive view of DBMS security, or whether they should be intensively and dynamically inspected by DBMS holders by referring to Internet of Things Search Engines moving towards a sustainable and resilient digitized environment. The study brings attention to this problem and make you think about data security before looking for and introducing more advanced security and protection mechanisms, which, in the absence of the above, may bring no value.
Other presentations delivered during this session were “Information Security Risk Awareness Survey of non-governmental Organization in Saudi Arabia”, “Fake news and threats to IoT – the crucial aspects of cyberspace in the times of cyber war” and “Minecraft as a Tool to Enhance Engagement in Higher Education” – both were incredibly interesting, and all three talks were delivered by females, where only the moderator of the session was a male researcher, which he found to be very specific, given the topic and ICT orientation – not a very typical case 🙂 But, nevertheless, we managed to have a great session and a very lively and fruitful discussion, mostly around GDPR-related questions, which seems to be one of the hottest areas of discussion for people representing different ICT “subbranches”. The main question that we discussed was – is the GDPR more a supportive tool and a “great thing” or rather a “headache” that sometimes even interferes with development.
In addition, shortly before the start of the event, I was asked to become a moderator of the panel “Business in the era of pervasive digitalization“. Although, as you may know, this is not exactly in line with my area of expertise, it is in line with what I am interested in. This is not surprising, since both management, business, the economics are very closely connected and dependent on ICT. Moreover, they affect ICT, thereby pointing out the critical areas that we as IT-people need to refer to. All in all, we had a great session with excellent talks and lively discussion at the end of the session, where we discussed different session-related topics, shared our experience, thoughts etc. Although it was a brilliant experience, there is one thing that made it even better… A day later, a ceremony was held where the best contributions of the forum were announced and I was named the best panel moderator as a recognition of “the academic merit, quality of moderation, scheduling, and discussion held during the panel”!!!
These were wonderful three days of the forum with very positive emotions and so many roles – panel organizer, speaker / presenter, program committee member and panel moderator with the cherry on the cake and such a great end of the event. Thank you Research and Innovation Forum!!! Even being at home and participating online, you managed to give us an absolute amazing experience and even the feeling that we were all together in Athens!