The role of Generative AI is the subject for debates in almost every domain today, and the open data (ecosystem) domain is no exception. Here’s my two cents on this with the blog post “Generative AI Role in Shaping the Future of Open Data Ecosystems: Synergies amidst Paradoxes”. In this blog post, I present some personal observations and predictions on how Generative AI will stop open “data winter” or even give an impetus to the “data spring” the call for what has been made recently. While these steps may be many and different, one obvious element that could affect the current state of affairs is Artificial Intelligence, particularly in the form of Generative AI. Along with this “forecast” and high-level discussion that is expected to be made more in-depth and likely evidence-based (since, together with my colleagues and students, we are already working in this direction), some paradoxes are mentioned among this symbiotic relationship between Generative AI and open data (ecosystem)…
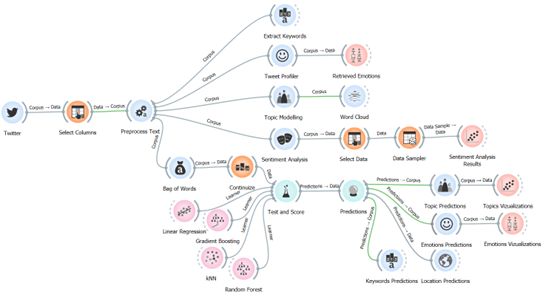
In this paper we present a predictive analytics-driven decision framework based on machine learning and data mining methods and techniques. We then demonstrate it in action by predicting sentiments and emotions in social media posts as a use-case choosing perhaps the trendiest topic – ChatGPT. In other words we check whether it is eternal love and complete trust or rather 🤬?
Why PA?
Predictive Analytics are seen to be useful in business, medical/ healthcare domain, incl. but not limited to crisis management, where, in addition to health-related crises, Predictive Analytics have proven useful in natural disasters management, industrial use-cases, such as energy to forecast supply and demand, predict the impact of equipment costs, downtimes / outages etc., aerospace to predict the impact of specific maintenance operations on aircraft reliability, fuel use, and uptime, while the biggest airlines – to predict travel patterns, setting ticket prices and flight schedules as well as predict the impact of, e.g., price changes, policy changes, and cancellations. And, of course, business process management and specifically retail, where Predictive Analytics allows retailers to follow customers in real-time, delivering targeted marketing and incentives, forecast inventory requirements, and configure their website (or store) to increase sales. It business process management area, in turn, Predictive Analytics give rise to what is called predictive process monitoring (PPM). Predictive Analytics uses were also found in Smart Cities and Smart Transportation domain, i.e. to support smart transportation services using open data, but also in education, i.e., to predict performance in MOOCs.
This popularity can be easily explained by examining their key strategic objectives, which IBM (Siegel, 2015) has summarized as: (1) competition – to secure the most powerful and unique stronghold of competitiveness, (2) growth – to increase sales and keep customers competitively, (3) enforcement – to maintain business integrity by managing fraud, (4) improvement – to advance core business capacity competitively, (5) satisfaction – to meet rising consumer expectations, (6) learning – to employ today’s most advanced analytics, (7) acting – to render business intelligence and analytics truly effective actionable. Marketing, sales, fraud detection, call center and core businesses of business units, same as customers and the enterprise as a whole are expected to gain benefits, which makes PA a “must”.
And although according to (MicroStrategy, 2020), in 2020, 52% of companies worldwide used predictive analytics to optimize operations as part of business intelligence platform solution, although so far, predictive analytics have been used mostly by large companies (65% of companies with $100 million to $500 million in revenue, and 46% of companies under $10 million in revenue), with less adoption in medium-sized companies, not to say about small companies.
Based on management theory and Gartner’s Business Intelligence and Performance Management Maturity Model, our framework covers four management levels of business intelligence – (a) Operational, (b) Tactical, (c) Strategic and (d) Pervasive. These are the levels that determine the need to manage data in organizations, transform them into information and turn them into knowledge, which is also the basis for making forecasts. The end result of applying it for business purposes is to generate effective solutions for each of these levels.
Many thanks to my co-authors – Radka and Otmane, who invited me to contribute to this study, and drove the entire process!
Cite paper as:
O. Azeroual, R. Nacheva, A. Nikiforova, U. Störl, and A. Fraisse. 2023. Predictive Analytics intelligent decision-making framework and testing it through sentiment analysis on Twitter data. In Proceedings of the 24th International Conference on Computer Systems and Technologies (CompSysTech ’23). Association for Computing Machinery, New York, NY, USA, 42–53. https://doi.org/10.1145/3606305.3606309
This post is dedicated to two very pleasant events for me, namely the international Open Data Day 🎉🍾🥂, and the announcement of the keynote talk that I was kindly invited to deliver at the 5th International Conference on Advanced Research Methods and Analytics (CARMA) organized and sponsored by Universidad de Sevilla, Cátedra Metropol Parasol, Cátedra Digitalización Empresarial, IBM, Universitat Politècnica de València, Joint Research Center – European Commission and 🥁 🥁 🥁 Coca-Cola – what a delicious conference!🍸🍸🍸
CARMA is a forum for researchers and practitioners to exchange ideas and advances on how emerging research methods and sources are applied to different fields of social sciences as well as to discuss current and future challenges with main focus on the topics such as Internet and Big Data sources in economics and social sciences including Social media and public opinion mining, Web scraping, Google Trends and Search Engine data, Geospatial and mobile phone data, Open data and public data, Big Data methods in economics and social sciences such as Sentiment analysis, Internet econometrics, AI and Machine learning applications, Statistical learning, Information quality and assessment, Crowdsourcing, Natural Language processing, Explainability and interpretability, the applications of the above including but not limited to Politics and social media, Sustainability and development, Finance applications, Official statistics, Forecasting and nowcasting, Bibliometrics and sciencetometrics, Social and consumer behaviour, mobility patterns, eWOM and social media marketing, Labor market, Business analytics with social media, Advances in travel, tourism and leisure, Digital management, Marketing Intelligence analytics, Data governance, and Digital transition and global society, which, in turn, expects contributions in relation to Privacy and legal aspects, Electronic Government, Data Economy, Smart Cities, Industry adoption.
And as almost each and every conference, CARMA expects to have keynotes, which are two – Patrick Mikalef, who will talk about Responsible AI and Big Data Analytics, and me, whose keynote talk will be devoted to the topics I studied in recent years titled “Public data ecosystems in and for smart cities: how to make open / Big / smart / geo data ecosystems value-adding for SDG-compliant Smart Living and Society 5.0?” Sounds interesting? (I hope so) Stay tuned to know more! And return back, since I plan to reflect on the content of both talks and the conference in general.
The CARMA 2023 conference will be held on 28 June – 30 June 2023 in the University of Seville.
Huge amount of data is being generated and transmitted everyday. To be able to deal with this data, extract useful information from it, store it, transmit it, and represent it, intelligent technologies and applications are needed. The International Conference on Intelligent Data Science Technologies and Applications (IDSTA) is a peer reviewed conference, whose objective is to advance the Data Science field by giving an opportunity for researchers, engineers, and practitioners to present their latest findings in the field. It will also invite key persons in the field to share their current knowledge and their future expectations for the field. Topics of interest for submission include, but are not limited to:
💡Applied Public Affairs, incl. but not limited to Campaign Management, Mass Communication Politics, Political Analysis, Survey Sampling 💡Business Analytics, incl. but not limited to Stock Market Analysis, Predictive Analytics, Business Intelligence 💡Finance, incl. but not limited to Risk Management, Algorithmic Trading, Fraud Detection, Financial Analysis 💡Computer Science, incl. but not limited to Database Management Systems, Scientific Computing, Computer Vision, Fuzzy Computing, Feature Selection, Neural Networks, Deep Learning, Meta-Learning, Process Mining, Artificial Intelligence, Data Mining, Big Data, Web Analytics, Text Mining, Natural Language Processing, Sentiment Analysis, Social Media Analysis, Data Fusion, Performance Analysis and Evaluation, Evolutionary Computing and Optimization, Hybrid Methods, Granular Computing, Recommender Systems, Data Visualization, Predictive Maintenance, Internet of Things (IoT), Web Scraping 💡Sustainability, incl. but not limited to Datasets on Sustainability, Sustainability Modeling, Energy Sustainability, Water Sustainability, Environmental Sustainability, Risk Analysis 💡Cybersecurity, incl. but not limited to Data Privacy and Security, Network Security, Communication Security, Cryptography, Fraud Detection, Blockchain 💡Environmental Science, incl. but not limited to GIS, Climatographic, Remote Sensing, Spatial Data Analysis, Weather Prediction and Tracking, 💡Biotechnologies, incl. but not limited to Gnome Analysis, Drug Discovery and Screening and Side Effect Analysis, Structural and Folding Pattern, Disease Discovery and Classification, Bioinformatics, Next-Gen Sequencing 💡Smart City, incl. but not limited to City Data Management, Smart Traffic, Surveillance, Location-Based Services, Robotics 💡Human Behaviour Understanding 💡Semi-Structured and Unstructured Data 💡Pattern Recognition 💡Transparency in Research Data 💡Data and Information Quality 💡GPU Computing 💡Crowdsourcing
🗓️🗓️🗓️ IMPORTANT DATES
Paper submission: March 15, 2023
Acceptance notification: May 20th, 2023
Full paper camera-ready submission: October 1st, 2023 Conference Dates: October 24-26, 2023
All papers that are accepted, registered, and presented in IDSTA2023 and the workshops co-located with it will be submitted to IEEEXplore for possible publication. For any inquiries, contact intelligenttechorg@gmail.com.
Submit the paper and meet our team in Kuwait in October, 2023!
Last week I had the pleasure of taking part in a Data Science Seminar titled “When, Why and How? The Importance of Business Intelligence“. In this seminar, organized by the Institute of Computer Science (University of Tartu) in cooperation with Swedbank, we (me, Mohammad Gharib, Jurgen Koitsalu, Igor Artemtsuk) discussed the importance of BI with some focus on data quality. More precisely, 2 of 4 talks were delivered by representatives of the University of Tartu and were more theoretical in nature, where we both decided to focus our talks on data quality (for my talk, however, this was not the main focus this time), while another two talks were delivered by representatives of Swedbank, mainly elaborating on BI – what it can give, what it already gives, how it is achieved and much more. These talks were followed by a panel moderated by prof. Marlon Dumas.
In a bit more detail…. In my presentation I talked about:
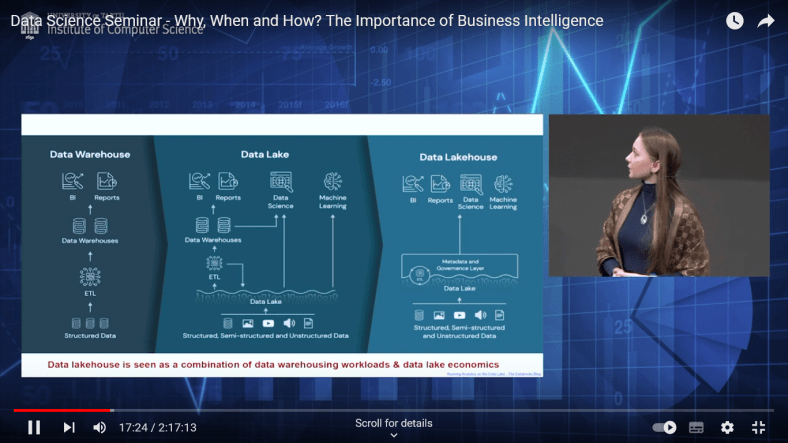
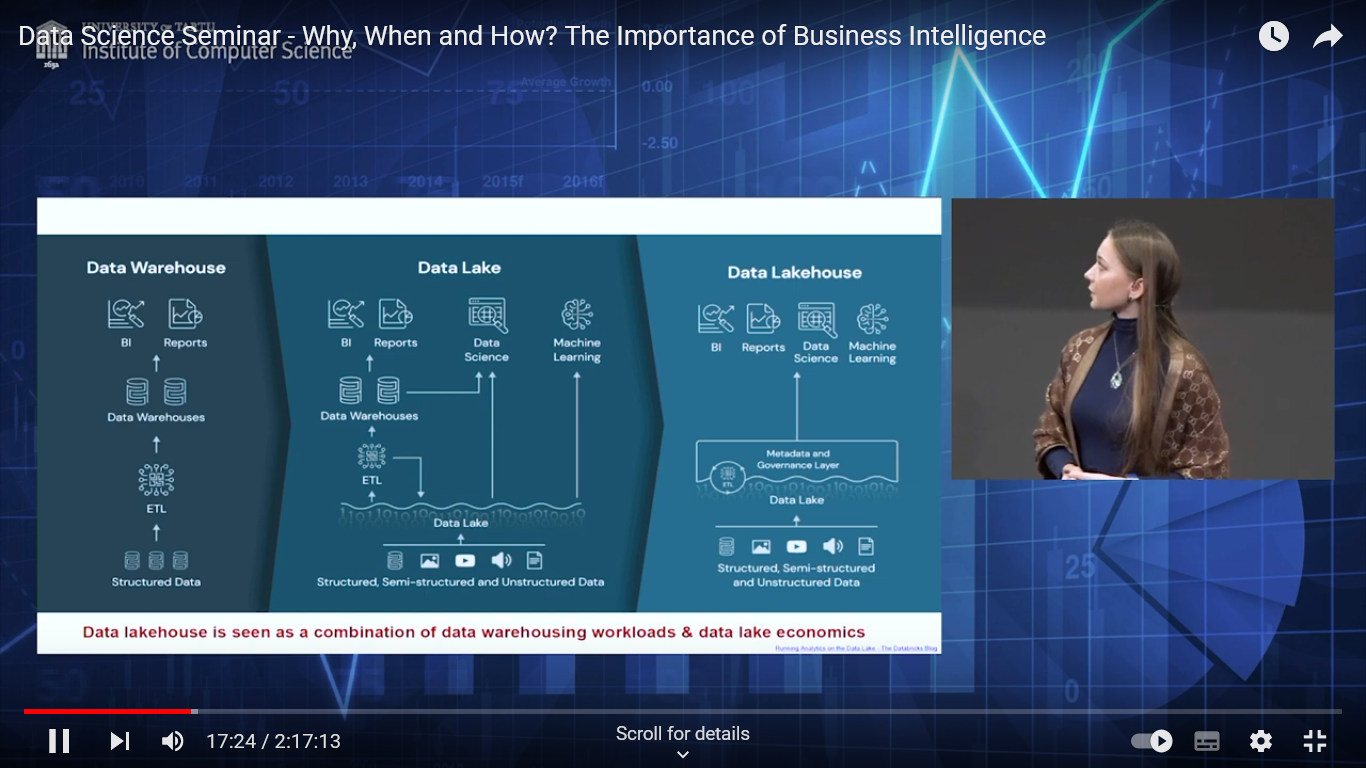
“Data warehouse vs. data lake – what are they and what is the difference between them?” – in a very few words – structured vs unstructured, static vs dynamic (real-time data), schema-on-write vs schema on-read, ETL vs ELT. With further elaboration on What are their goals and purposes? What is their target audience? What are their pros and cons?
“Is the Data warehouse the only data repository suitable for BI?” – no, (today) data lakes can also be suitable. And even more, both are considered the key to “a single version of the truth”. Although, if descriptive BI is the only purpose, it might still be better to stay within data warehouse. But, if you want to either have predictive BI or use your data for ML (or do not have a specific idea on how you want to use the data, but want to be able to explore your data effectively and efficiently), you know that a data warehouse might not be the best option.
“So, the data lake will save my resources a lot, because I do not have to worry about how to store /allocate the data – just put it in one storage and voila?!” – no, in this case your data lake will turn into a data swamp! And you are forgetting about the data quality you should (must!) be thinking of!
“But how do you prevent the data lake from becoming a data swamp?” – in short and simple terms – proper data governance & metadata management is the answer (but not as easy as it sounds – do not forget about your data engineer and be friendly with him [always… literally always :D) and also think about the culture in your organization.
“So, the use of a data warehouse is the key to high quality data?” – no, it is not! Having ETL do not guarantee the quality of your data (transform&load is not data quality management). Think about data quality regardless of the repository!
“Are data warehouses and data lakes the only options to consider or are we missing something?“– true! Data lakehouse!
“If a data lakehouse is a combination of benefits of a data warehouse and data lake, is it a silver bullet?“– no, it is not! This is another option (relatively immature) to consider that may be the best bit for you, but not a panacea. Dealing with data is not easy (still)…
In addition, in this talk I also briefly introduced the ongoing research into the integration of the data lake as a data repository and data wrangling seeking for an increased data quality in IS. In short, this is somewhat like an improved data lakehouse, where we emphasize the need of data governance and data wrangling to be integrated to really get the benefits that the data lakehouses promise (although we still call it a data lake, since a data lakehouse, although not a super new concept, is still debated a lot, including but not limited to, on the definition of such).
However, my colleague Mohamad Gharib discussed what DQ and more specifically data quality requirements, why they really matter, and provided a very interesting perspective of how to define high quality data, which further would serve as the basis for defining these requirements.
All in all, although we did not know each other before and had a very limited idea of what each of us will talk about, we all admitted that this seminar turned out to be very coherent, where we and our talks, respectively, complemented each other, extending some previously touched but not thoroughly elaborated points. This allowed us not only to make the seminar a success, but also to establish a very lively discussion (although the prevailing part of this discussion took place during the coffee break – as it usually happens – so, unfortunately, is not available in the recordings, the link to which is available below).