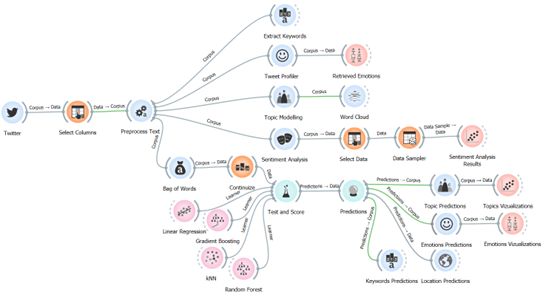
This paper alert is dedicated to “Predictive Analytics intelligent decision-making framework and testing it through sentiment analysis on Twitter data” (authors: Otmane Azeroual, Radka Nacheva, Anastasija Nikiforova, Uta Störl, Amel Fraisse) paper, which is now publicly available in ACM Digital Library!
In this paper we present a predictive analytics-driven decision framework based on machine learning and data mining methods and techniques. We then demonstrate it in action by predicting sentiments and emotions in social media posts as a use-case choosing perhaps the trendiest topic – ChatGPT. In other words we check whether it is eternal love and complete trust or rather 🤬?
Why PA?
Predictive Analytics are seen to be useful in business, medical/ healthcare domain, incl. but not limited to crisis management, where, in addition to health-related crises, Predictive Analytics have proven useful in natural disasters management, industrial use-cases, such as energy to forecast supply and demand, predict the impact of equipment costs, downtimes / outages etc., aerospace to predict the impact of specific maintenance operations on aircraft reliability, fuel use, and uptime, while the biggest airlines – to predict travel patterns, setting ticket prices and flight schedules as well as predict the impact of, e.g., price changes, policy changes, and cancellations. And, of course, business process management and specifically retail, where Predictive Analytics allows retailers to follow customers in real-time, delivering targeted marketing and incentives, forecast inventory requirements, and configure their website (or store) to increase sales. It business process management area, in turn, Predictive Analytics give rise to what is called predictive process monitoring (PPM). Predictive Analytics uses were also found in Smart Cities and Smart Transportation domain, i.e. to support smart transportation services using open data, but also in education, i.e., to predict performance in MOOCs.
This popularity can be easily explained by examining their key strategic objectives, which IBM (Siegel, 2015) has summarized as: (1) competition – to secure the most powerful and unique stronghold of competitiveness, (2) growth – to increase sales and keep customers competitively, (3) enforcement – to maintain business integrity by managing fraud, (4) improvement – to advance core business capacity competitively, (5) satisfaction – to meet rising consumer expectations, (6) learning – to employ today’s most advanced analytics, (7) acting – to render business intelligence and analytics truly effective actionable. Marketing, sales, fraud detection, call center and core businesses of business units, same as customers and the enterprise as a whole are expected to gain benefits, which makes PA a “must”.
And although according to (MicroStrategy, 2020), in 2020, 52% of companies worldwide used predictive analytics to optimize operations as part of business intelligence platform solution, although so far, predictive analytics have been used mostly by large companies (65% of companies with $100 million to $500 million in revenue, and 46% of companies under $10 million in revenue), with less adoption in medium-sized companies, not to say about small companies.
Based on management theory and Gartner’s Business Intelligence and Performance Management Maturity Model, our framework covers four management levels of business intelligence – (a) Operational, (b) Tactical, (c) Strategic and (d) Pervasive. These are the levels that determine the need to manage data in organizations, transform them into information and turn them into knowledge, which is also the basis for making forecasts. The end result of applying it for business purposes is to generate effective solutions for each of these levels.

Sounds catchy? Read the paper here.
Many thanks to my co-authors – Radka and Otmane, who invited me to contribute to this study, and drove the entire process!
Cite paper as:
O. Azeroual, R. Nacheva, A. Nikiforova, U. Störl, and A. Fraisse. 2023. Predictive Analytics intelligent decision-making framework and testing it through sentiment analysis on Twitter data. In Proceedings of the 24th International Conference on Computer Systems and Technologies (CompSysTech ’23). Association for Computing Machinery, New York, NY, USA, 42–53. https://doi.org/10.1145/3606305.3606309